AI efficiency
-
Manifold-Constrained Hyper-Connections in AI
Read Full Article: Manifold-Constrained Hyper-Connections in AI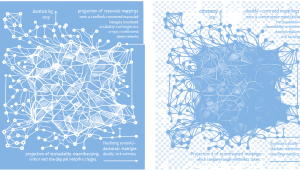 DeepSeek-AI introduces Manifold-Constrained Hyper-Connections (mHC) to tackle the instability and scalability challenges of Hyper-Connections (HC) in neural networks. The approach involves projecting residual mappings onto a constrained manifold using doubly stochastic matrices via the Sinkhorn-Knopp algorithm, which helps maintain the identity mapping property while benefiting from enhanced residual streams. This method has shown to improve training stability and scalability in large-scale language model pretraining, with negligible additional system overhead. Such advancements are crucial for developing more efficient and robust AI models capable of handling complex tasks at scale.
DeepSeek-AI introduces Manifold-Constrained Hyper-Connections (mHC) to tackle the instability and scalability challenges of Hyper-Connections (HC) in neural networks. The approach involves projecting residual mappings onto a constrained manifold using doubly stochastic matrices via the Sinkhorn-Knopp algorithm, which helps maintain the identity mapping property while benefiting from enhanced residual streams. This method has shown to improve training stability and scalability in large-scale language model pretraining, with negligible additional system overhead. Such advancements are crucial for developing more efficient and robust AI models capable of handling complex tasks at scale.
-
AI Efficiency Layoffs: Reality vs. Corporate Narrative
Read Full Article: AI Efficiency Layoffs: Reality vs. Corporate Narrative The recent wave of layoffs in the tech industry, justified by claims of increased developer efficiency through AI tools, reveals a disconnect between corporate narratives and on-the-ground realities. While companies argue that AI tools like Copilot have boosted developer velocity, leading to reduced headcounts, the reality is that senior engineers are overwhelmed by the need to review extensive AI-generated code that often lacks depth and context. This has led to increased "code churn," where code is written and rewritten without effectively solving problems, and has resulted in burnout among engineers. The situation underscores the challenges of integrating new technologies into workflows, as initial productivity dips are expected, yet companies have prematurely reduced resources, exacerbating the issue. This matters because it highlights the potential pitfalls of relying solely on AI for efficiency gains without considering the broader impacts on team dynamics and productivity.
The recent wave of layoffs in the tech industry, justified by claims of increased developer efficiency through AI tools, reveals a disconnect between corporate narratives and on-the-ground realities. While companies argue that AI tools like Copilot have boosted developer velocity, leading to reduced headcounts, the reality is that senior engineers are overwhelmed by the need to review extensive AI-generated code that often lacks depth and context. This has led to increased "code churn," where code is written and rewritten without effectively solving problems, and has resulted in burnout among engineers. The situation underscores the challenges of integrating new technologies into workflows, as initial productivity dips are expected, yet companies have prematurely reduced resources, exacerbating the issue. This matters because it highlights the potential pitfalls of relying solely on AI for efficiency gains without considering the broader impacts on team dynamics and productivity.
-
Temporal LoRA: Dynamic Adapter Router for GPT-2
Read Full Article: Temporal LoRA: Dynamic Adapter Router for GPT-2![[Experimental] "Temporal LoRA": A dynamic adapter router that switches context (Code vs. Lit) with 100% accuracy. Proof of concept on GPT-2.](https://www.tweakedgeek.com/wp-content/uploads/2026/01/featured-article-8275-300x171.png) Temporal LoRA introduces a dynamic adapter router that allows models to switch between different contexts, such as coding and literature, with 100% accuracy. By training distinct LoRA adapters for different styles and implementing a "Time Mixer" network, the system can dynamically activate the appropriate adapter based on input context, maintaining model stability while allowing for flexible task switching. This approach provides a promising method for integrating Mixture of Experts (MoE) in larger models without the need for extensive retraining, enabling seamless "hot-swapping" of skills and enhancing multi-tasking capabilities. This matters because it offers a scalable solution for improving AI model adaptability and efficiency in handling diverse tasks.
Temporal LoRA introduces a dynamic adapter router that allows models to switch between different contexts, such as coding and literature, with 100% accuracy. By training distinct LoRA adapters for different styles and implementing a "Time Mixer" network, the system can dynamically activate the appropriate adapter based on input context, maintaining model stability while allowing for flexible task switching. This approach provides a promising method for integrating Mixture of Experts (MoE) in larger models without the need for extensive retraining, enabling seamless "hot-swapping" of skills and enhancing multi-tasking capabilities. This matters because it offers a scalable solution for improving AI model adaptability and efficiency in handling diverse tasks.
-
Optimize Your 8+32+ System with Granite 4.0 Small
Read Full Article: Optimize Your 8+32+ System with Granite 4.0 Small A ThinkPad P15 with 32GB of RAM and an 8GB Quadro GPU, typically only suitable for 7-8 billion parameter models, can efficiently handle larger tasks using Granite 4.0 Small. This model, a hybrid transformer and mamba, maintains speed as context increases, processing a 50-page document (~50.5k tokens) at approximately 7 tokens per second. This performance makes it a practical choice for users needing to manage large data sets without sacrificing speed. Understanding how to optimize hardware with the right models can significantly enhance productivity and efficiency for users with similar setups.
A ThinkPad P15 with 32GB of RAM and an 8GB Quadro GPU, typically only suitable for 7-8 billion parameter models, can efficiently handle larger tasks using Granite 4.0 Small. This model, a hybrid transformer and mamba, maintains speed as context increases, processing a 50-page document (~50.5k tokens) at approximately 7 tokens per second. This performance makes it a practical choice for users needing to manage large data sets without sacrificing speed. Understanding how to optimize hardware with the right models can significantly enhance productivity and efficiency for users with similar setups.
-
Chrome Extension for Navigating Long AI Chats
Read Full Article: Chrome Extension for Navigating Long AI Chats Long AI chat conversations often become cumbersome to scroll through and reuse, especially with platforms like ChatGPT, Claude, and Gemini. To address this, a new Chrome extension has been developed that facilitates easier navigation through lengthy chats by allowing users to jump between prompts. Additionally, the extension offers the functionality to export entire conversations in various formats such as Markdown, PDF, JSON, and text. This innovation is significant as it enhances user experience and efficiency when dealing with extensive AI-generated dialogues.
Long AI chat conversations often become cumbersome to scroll through and reuse, especially with platforms like ChatGPT, Claude, and Gemini. To address this, a new Chrome extension has been developed that facilitates easier navigation through lengthy chats by allowing users to jump between prompts. Additionally, the extension offers the functionality to export entire conversations in various formats such as Markdown, PDF, JSON, and text. This innovation is significant as it enhances user experience and efficiency when dealing with extensive AI-generated dialogues.
-
LoongFlow: Revolutionizing AGI Evolution
Read Full Article: LoongFlow: Revolutionizing AGI Evolution LoongFlow introduces a new approach to artificial general intelligence (AGI) evolution by integrating a Cognitive Core that follows a Plan-Execute-Summarize model, significantly enhancing efficiency and reducing costs compared to traditional frameworks like OpenEvolve. This method effectively eliminates the randomness of previous evolutionary models, achieving impressive results such as 14 Kaggle Gold Medals without human intervention and operating at just 1/20th of the compute cost. By open-sourcing LoongFlow, the developers aim to transform the landscape of AGI evolution, emphasizing the importance of strategic thinking over random mutations. This matters because it represents a significant advancement in making AGI development more efficient and accessible.
LoongFlow introduces a new approach to artificial general intelligence (AGI) evolution by integrating a Cognitive Core that follows a Plan-Execute-Summarize model, significantly enhancing efficiency and reducing costs compared to traditional frameworks like OpenEvolve. This method effectively eliminates the randomness of previous evolutionary models, achieving impressive results such as 14 Kaggle Gold Medals without human intervention and operating at just 1/20th of the compute cost. By open-sourcing LoongFlow, the developers aim to transform the landscape of AGI evolution, emphasizing the importance of strategic thinking over random mutations. This matters because it represents a significant advancement in making AGI development more efficient and accessible.
-
Lynkr – Multi-Provider LLM Proxy
Read Full Article: Lynkr – Multi-Provider LLM Proxy The landscape of local Large Language Models (LLMs) is rapidly advancing, with llama.cpp emerging as a preferred choice among redditors for its superior performance, transparency, and features compared to Ollama. While several local LLMs have proven effective for various tasks, the latest Llama models have received mixed reviews. The rising costs of hardware, especially VRAM and DRAM, pose challenges for running local LLMs. For those seeking further insights and community discussions, several subreddits offer valuable resources and support. Understanding these developments is crucial as they impact the accessibility and efficiency of AI technologies in local settings.
The landscape of local Large Language Models (LLMs) is rapidly advancing, with llama.cpp emerging as a preferred choice among redditors for its superior performance, transparency, and features compared to Ollama. While several local LLMs have proven effective for various tasks, the latest Llama models have received mixed reviews. The rising costs of hardware, especially VRAM and DRAM, pose challenges for running local LLMs. For those seeking further insights and community discussions, several subreddits offer valuable resources and support. Understanding these developments is crucial as they impact the accessibility and efficiency of AI technologies in local settings.
-
AI Model Learns While Reading
Read Full Article: AI Model Learns While Reading A collaborative effort by researchers from Stanford, NVIDIA, and UC Berkeley has led to the development of TTT-E2E, a model that addresses long-context modeling as a continual learning challenge. Unlike traditional approaches that store every token, TTT-E2E continuously trains while reading, efficiently compressing context into its weights. This innovation allows the model to achieve full-attention performance at 128K tokens while maintaining a constant inference cost. Understanding and improving how AI models process extensive contexts can significantly enhance their efficiency and applicability in real-world scenarios.
A collaborative effort by researchers from Stanford, NVIDIA, and UC Berkeley has led to the development of TTT-E2E, a model that addresses long-context modeling as a continual learning challenge. Unlike traditional approaches that store every token, TTT-E2E continuously trains while reading, efficiently compressing context into its weights. This innovation allows the model to achieve full-attention performance at 128K tokens while maintaining a constant inference cost. Understanding and improving how AI models process extensive contexts can significantly enhance their efficiency and applicability in real-world scenarios.
-
The Handyman Principle: AI’s Memory Challenges
Read Full Article: The Handyman Principle: AI’s Memory ChallengesThe Handyman Principle explores the concept of AI systems frequently "forgetting" information, akin to a handyman who must focus on the task at hand rather than retaining all past details. This phenomenon is attributed to the limitations in current AI architectures, which prioritize efficiency and performance over long-term memory retention. By understanding these constraints, developers can better design AI systems that balance memory and processing capabilities. This matters because improving AI memory retention could lead to more sophisticated and reliable systems in various applications.
-
AI’s Shift from Hype to Practicality by 2026
Read Full Article: AI’s Shift from Hype to Practicality by 2026 In 2026, AI is expected to transition from the era of hype and massive language models to a more pragmatic and practical phase. The focus will shift towards deploying smaller, fine-tuned models that are cost-effective and tailored for specific applications, enhancing efficiency and integration into human workflows. World models, which allow AI systems to understand and interact with 3D environments, are anticipated to make significant strides, particularly in gaming, while agentic AI tools like Anthropic's Model Context Protocol will facilitate better integration into real-world systems. This evolution will likely emphasize augmentation over automation, creating new roles in AI governance and deployment, and paving the way for physical AI applications in devices like wearables and robotics. This matters because it signals a shift towards more sustainable and impactful AI technologies that are better integrated into everyday life and industry.
In 2026, AI is expected to transition from the era of hype and massive language models to a more pragmatic and practical phase. The focus will shift towards deploying smaller, fine-tuned models that are cost-effective and tailored for specific applications, enhancing efficiency and integration into human workflows. World models, which allow AI systems to understand and interact with 3D environments, are anticipated to make significant strides, particularly in gaming, while agentic AI tools like Anthropic's Model Context Protocol will facilitate better integration into real-world systems. This evolution will likely emphasize augmentation over automation, creating new roles in AI governance and deployment, and paving the way for physical AI applications in devices like wearables and robotics. This matters because it signals a shift towards more sustainable and impactful AI technologies that are better integrated into everyday life and industry.