AI tools
-
Google DeepMind & DOE Partner on AI for Science
Read Full Article: Google DeepMind & DOE Partner on AI for Science Google DeepMind is collaborating with the U.S. Department of Energy on the Genesis Mission, an initiative aimed at revolutionizing scientific research through advanced AI. This partnership will provide scientists at the DOE's 17 National Laboratories with access to cutting-edge AI tools, such as AI co-scientist, AlphaEvolve, and AlphaGenome, to accelerate breakthroughs in fields like energy, material science, and biomedical research. By leveraging AI, the mission seeks to overcome significant scientific challenges, reduce the time needed for discoveries, and enhance American research productivity. This collaboration underscores the transformative potential of AI in addressing global challenges, from disease to climate change. Why this matters: The integration of AI in scientific research could drastically accelerate innovation and problem-solving in critical areas, potentially leading to groundbreaking advancements and solutions to pressing global issues.
Google DeepMind is collaborating with the U.S. Department of Energy on the Genesis Mission, an initiative aimed at revolutionizing scientific research through advanced AI. This partnership will provide scientists at the DOE's 17 National Laboratories with access to cutting-edge AI tools, such as AI co-scientist, AlphaEvolve, and AlphaGenome, to accelerate breakthroughs in fields like energy, material science, and biomedical research. By leveraging AI, the mission seeks to overcome significant scientific challenges, reduce the time needed for discoveries, and enhance American research productivity. This collaboration underscores the transformative potential of AI in addressing global challenges, from disease to climate change. Why this matters: The integration of AI in scientific research could drastically accelerate innovation and problem-solving in critical areas, potentially leading to groundbreaking advancements and solutions to pressing global issues.
-
Hosting Language Models on a Budget
Read Full Article: Hosting Language Models on a Budget Running your own large language model (LLM) can be surprisingly affordable and straightforward, with options like deploying TinyLlama on Hugging Face for free. Understanding the costs involved, such as compute, storage, and bandwidth, is crucial, as compute is typically the largest expense. For beginners or those with limited budgets, free hosting options like Hugging Face Spaces, Render, and Railway can be utilized effectively. Models like TinyLlama, DistilGPT-2, Phi-2, and Flan-T5-Small are suitable for various tasks and can be run on free tiers, providing a practical way to experiment and learn without significant financial investment. This matters because it democratizes access to advanced AI technology, enabling more people to experiment and innovate without prohibitive costs.
Running your own large language model (LLM) can be surprisingly affordable and straightforward, with options like deploying TinyLlama on Hugging Face for free. Understanding the costs involved, such as compute, storage, and bandwidth, is crucial, as compute is typically the largest expense. For beginners or those with limited budgets, free hosting options like Hugging Face Spaces, Render, and Railway can be utilized effectively. Models like TinyLlama, DistilGPT-2, Phi-2, and Flan-T5-Small are suitable for various tasks and can be run on free tiers, providing a practical way to experiment and learn without significant financial investment. This matters because it democratizes access to advanced AI technology, enabling more people to experiment and innovate without prohibitive costs.
-
Prompt Engineering for Data Quality Checks
Read Full Article: Prompt Engineering for Data Quality ChecksData teams are increasingly leveraging prompt engineering with large language models (LLMs) to enhance data quality and validation processes. Unlike traditional rule-based systems, which often struggle with unstructured data, LLMs offer a more adaptable approach by evaluating the coherence and context of data entries. By designing prompts that mimic human reasoning, data validation can become more intelligent and capable of identifying subtler issues such as mislabeled entries and inconsistent semantics. Embedding domain knowledge into prompts further enhances their effectiveness, allowing for automated and scalable data validation pipelines that integrate seamlessly into existing workflows. This shift towards LLM-driven validation represents a significant advancement in data governance, emphasizing smarter questions over stricter rules. This matters because it transforms data validation into a more efficient and intelligent process, enhancing data reliability and reducing manual effort.
-
Gemma Scope 2: Full Stack Interpretability for AI Safety
Read Full Article: Gemma Scope 2: Full Stack Interpretability for AI Safety Google DeepMind has unveiled Gemma Scope 2, a comprehensive suite of interpretability tools designed for the Gemma 3 language models, which range from 270 million to 27 billion parameters. This suite aims to enhance AI safety and alignment by allowing researchers to trace model behavior back to internal features, rather than relying solely on input-output analysis. Gemma Scope 2 employs sparse autoencoders (SAEs) to break down high-dimensional activations into sparse, human-inspectable features, offering insights into model behaviors such as jailbreaks, hallucinations, and sycophancy. The suite includes tools like skip transcoders and cross-layer transcoders to track multi-step computations across layers, and it is tailored for models tuned for chat to analyze complex behaviors. This release builds on the original Gemma Scope by expanding coverage to the entire Gemma 3 family, utilizing the Matryoshka training technique to enhance feature stability, and addressing interpretability across all layers of the models. The development of Gemma Scope 2 involved managing 110 petabytes of activation data and training over a trillion parameters, underscoring its scale and ambition in advancing AI safety research. This matters because it provides a practical framework for understanding and improving the safety of increasingly complex AI models.
Google DeepMind has unveiled Gemma Scope 2, a comprehensive suite of interpretability tools designed for the Gemma 3 language models, which range from 270 million to 27 billion parameters. This suite aims to enhance AI safety and alignment by allowing researchers to trace model behavior back to internal features, rather than relying solely on input-output analysis. Gemma Scope 2 employs sparse autoencoders (SAEs) to break down high-dimensional activations into sparse, human-inspectable features, offering insights into model behaviors such as jailbreaks, hallucinations, and sycophancy. The suite includes tools like skip transcoders and cross-layer transcoders to track multi-step computations across layers, and it is tailored for models tuned for chat to analyze complex behaviors. This release builds on the original Gemma Scope by expanding coverage to the entire Gemma 3 family, utilizing the Matryoshka training technique to enhance feature stability, and addressing interpretability across all layers of the models. The development of Gemma Scope 2 involved managing 110 petabytes of activation data and training over a trillion parameters, underscoring its scale and ambition in advancing AI safety research. This matters because it provides a practical framework for understanding and improving the safety of increasingly complex AI models.
-
Choosing the Right Language for Machine Learning
Read Full Article: Choosing the Right Language for Machine Learning Python remains the dominant programming language for machine learning due to its extensive libraries and user-friendly nature. However, other languages are also employed for specific tasks where performance or platform-specific needs dictate. C++ is favored for performance-critical components, while Julia, despite its limited adoption, is used by some for its machine learning capabilities. R is primarily utilized for statistical analysis and data visualization but also supports machine learning tasks. Go, Swift, Kotlin, Java, Rust, Dart, and Vala each offer unique advantages such as native code compilation, performance, and platform-specific benefits, making them viable options for certain machine learning applications. Understanding these languages alongside Python can enhance a developer's toolkit, allowing them to choose the best language for their specific needs in machine learning projects. This matters because having a diverse skill set in programming languages enables more efficient and effective solutions in machine learning, tailored to specific performance and platform requirements.
Python remains the dominant programming language for machine learning due to its extensive libraries and user-friendly nature. However, other languages are also employed for specific tasks where performance or platform-specific needs dictate. C++ is favored for performance-critical components, while Julia, despite its limited adoption, is used by some for its machine learning capabilities. R is primarily utilized for statistical analysis and data visualization but also supports machine learning tasks. Go, Swift, Kotlin, Java, Rust, Dart, and Vala each offer unique advantages such as native code compilation, performance, and platform-specific benefits, making them viable options for certain machine learning applications. Understanding these languages alongside Python can enhance a developer's toolkit, allowing them to choose the best language for their specific needs in machine learning projects. This matters because having a diverse skill set in programming languages enables more efficient and effective solutions in machine learning, tailored to specific performance and platform requirements.
-
MiniMax M2.1: Open Source SOTA for Dev & Agents
Read Full Article: MiniMax M2.1: Open Source SOTA for Dev & Agents MiniMax M2.1, now open source and available on Hugging Face, is setting new standards in real-world development and agent applications by achieving state-of-the-art (SOTA) performance on coding benchmarks such as SWE, VIBE, and Multi-SWE. Demonstrating superior capabilities, it surpasses notable models like Gemini 3 Pro and Claude Sonnet 4.5. With a configuration of 10 billion active parameters and a total of 230 billion parameters in a Mixture of Experts (MoE) architecture, MiniMax M2.1 offers significant advancements in computational efficiency and effectiveness for developers and AI agents. This matters because it provides the AI community with a powerful, open-source tool that enhances coding efficiency and innovation in AI applications.
MiniMax M2.1, now open source and available on Hugging Face, is setting new standards in real-world development and agent applications by achieving state-of-the-art (SOTA) performance on coding benchmarks such as SWE, VIBE, and Multi-SWE. Demonstrating superior capabilities, it surpasses notable models like Gemini 3 Pro and Claude Sonnet 4.5. With a configuration of 10 billion active parameters and a total of 230 billion parameters in a Mixture of Experts (MoE) architecture, MiniMax M2.1 offers significant advancements in computational efficiency and effectiveness for developers and AI agents. This matters because it provides the AI community with a powerful, open-source tool that enhances coding efficiency and innovation in AI applications.
-
Top Local LLMs of 2025
Read Full Article: Top Local LLMs of 2025 The year 2025 has been remarkable for open and local AI enthusiasts, with significant advancements in local language models (LLMs) like Minimax M2.1 and GLM4.7, which are now approaching the performance of proprietary models. Enthusiasts are encouraged to share their favorite models and detailed experiences, including their setups, usage nature, and tools, to help evaluate these models' capabilities given the challenges of benchmarks and stochasticity. The discussion is organized by application categories such as general use, coding, creative writing, and specialties, with a focus on open-weight models. Participants are also advised to classify their recommendations based on model memory footprint, as using multiple models for different tasks is beneficial. This matters because it highlights the progress and potential of open-source LLMs, fostering a community-driven approach to AI development and application.
The year 2025 has been remarkable for open and local AI enthusiasts, with significant advancements in local language models (LLMs) like Minimax M2.1 and GLM4.7, which are now approaching the performance of proprietary models. Enthusiasts are encouraged to share their favorite models and detailed experiences, including their setups, usage nature, and tools, to help evaluate these models' capabilities given the challenges of benchmarks and stochasticity. The discussion is organized by application categories such as general use, coding, creative writing, and specialties, with a focus on open-weight models. Participants are also advised to classify their recommendations based on model memory footprint, as using multiple models for different tasks is beneficial. This matters because it highlights the progress and potential of open-source LLMs, fostering a community-driven approach to AI development and application.
-
LexiBrief: Precise Legal Text Summarization
Read Full Article: LexiBrief: Precise Legal Text Summarization LexiBrief is a specialized model designed to address the challenges of summarizing legal texts with precision and minimal loss of specificity. Built on the Google FLAN-T5 architecture and fine-tuned using BillSum with QLoRA for efficiency, LexiBrief aims to generate concise summaries that preserve the essential clauses and intent of legal and policy documents. This approach seeks to improve upon existing open summarizers that often oversimplify complex legal language. LexiBrief is available on Hugging Face, inviting feedback from those experienced in factual summarization and domain-specific language model tuning. This advancement is crucial as it enhances the accuracy and reliability of legal document summarization, a vital tool for legal professionals and policymakers.
LexiBrief is a specialized model designed to address the challenges of summarizing legal texts with precision and minimal loss of specificity. Built on the Google FLAN-T5 architecture and fine-tuned using BillSum with QLoRA for efficiency, LexiBrief aims to generate concise summaries that preserve the essential clauses and intent of legal and policy documents. This approach seeks to improve upon existing open summarizers that often oversimplify complex legal language. LexiBrief is available on Hugging Face, inviting feedback from those experienced in factual summarization and domain-specific language model tuning. This advancement is crucial as it enhances the accuracy and reliability of legal document summarization, a vital tool for legal professionals and policymakers.
-
Practical Agentic Coding with Google Jules
Read Full Article: Practical Agentic Coding with Google Jules Google Jules is an autonomous agentic coding assistant developed by Google DeepMind, designed to integrate with existing code repositories and autonomously perform development tasks. It operates asynchronously in the background using a cloud virtual machine, allowing developers to focus on other tasks while it handles complex coding operations. Jules analyzes entire codebases, drafts plans, executes modifications, tests changes, and submits pull requests for review. It supports tasks like code refactoring, bug fixing, and generating unit tests, and provides audio summaries of recent commits. Interaction options include a command-line interface and an API for deeper customization and integration with tools like Slack or Jira. While Jules excels in certain tasks, developers must review its plans and changes to ensure alignment with project standards. As agentic coding tools like Jules evolve, they offer significant potential to enhance coding workflows, making it crucial for developers to explore and adapt to these technologies. Why this matters: Understanding and leveraging agentic coding tools like Google Jules can significantly enhance development efficiency and adaptability, positioning developers to better meet the demands of evolving tech landscapes.
Google Jules is an autonomous agentic coding assistant developed by Google DeepMind, designed to integrate with existing code repositories and autonomously perform development tasks. It operates asynchronously in the background using a cloud virtual machine, allowing developers to focus on other tasks while it handles complex coding operations. Jules analyzes entire codebases, drafts plans, executes modifications, tests changes, and submits pull requests for review. It supports tasks like code refactoring, bug fixing, and generating unit tests, and provides audio summaries of recent commits. Interaction options include a command-line interface and an API for deeper customization and integration with tools like Slack or Jira. While Jules excels in certain tasks, developers must review its plans and changes to ensure alignment with project standards. As agentic coding tools like Jules evolve, they offer significant potential to enhance coding workflows, making it crucial for developers to explore and adapt to these technologies. Why this matters: Understanding and leveraging agentic coding tools like Google Jules can significantly enhance development efficiency and adaptability, positioning developers to better meet the demands of evolving tech landscapes.
-
Building Self-Organizing Zettelkasten Knowledge Graphs
Read Full Article: Building Self-Organizing Zettelkasten Knowledge Graphs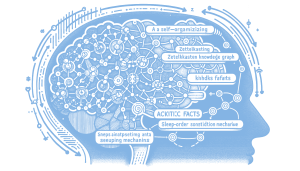 Building a self-organizing Zettelkasten knowledge graph with sleep-consolidation mechanisms represents a significant leap in Agentic AI, mimicking the human brain's ability to organize and consolidate information. By using Google's Gemini, the system autonomously decomposes inputs into atomic facts, semantically links them, and consolidates these into higher-order insights, akin to how the brain processes and stores memories. This approach allows the agent to actively understand and adapt to evolving project contexts, addressing the issue of fragmented context in long-running AI interactions. The implementation includes robust error handling for API constraints, ensuring smooth operation even under heavy processing loads. This matters because it demonstrates the potential for creating more intelligent, autonomous agents that can manage complex information dynamically, paving the way for advanced AI applications.
Building a self-organizing Zettelkasten knowledge graph with sleep-consolidation mechanisms represents a significant leap in Agentic AI, mimicking the human brain's ability to organize and consolidate information. By using Google's Gemini, the system autonomously decomposes inputs into atomic facts, semantically links them, and consolidates these into higher-order insights, akin to how the brain processes and stores memories. This approach allows the agent to actively understand and adapt to evolving project contexts, addressing the issue of fragmented context in long-running AI interactions. The implementation includes robust error handling for API constraints, ensuring smooth operation even under heavy processing loads. This matters because it demonstrates the potential for creating more intelligent, autonomous agents that can manage complex information dynamically, paving the way for advanced AI applications.