PyTorch
-
Clean PyTorch Implementations of 50+ ML Papers
Read Full Article: Clean PyTorch Implementations of 50+ ML Papers![[D] Clean, self-contained PyTorch re-implementations of 50+ ML papers (GANs, diffusion, meta-learning, 3D)](https://www.tweakedgeek.com/wp-content/uploads/2026/01/featured-article-8490-300x171.png) A repository offers clean and self-contained PyTorch implementations of over 50 machine learning papers, covering areas like GANs, VAEs, diffusion models, meta-learning, and 3D reconstruction. These implementations are designed to remain true to the original methods while minimizing unnecessary code, making them easy to run and inspect. The goal is to reproduce key results where feasible, providing a valuable resource for understanding and experimenting with advanced machine learning concepts. This matters because it facilitates learning and experimentation in machine learning by providing accessible and concise code examples.
A repository offers clean and self-contained PyTorch implementations of over 50 machine learning papers, covering areas like GANs, VAEs, diffusion models, meta-learning, and 3D reconstruction. These implementations are designed to remain true to the original methods while minimizing unnecessary code, making them easy to run and inspect. The goal is to reproduce key results where feasible, providing a valuable resource for understanding and experimenting with advanced machine learning concepts. This matters because it facilitates learning and experimentation in machine learning by providing accessible and concise code examples.
-
VibeVoice TTS on DGX Spark: Fast & Responsive Setup
Read Full Article: VibeVoice TTS on DGX Spark: Fast & Responsive Setup Microsoft's VibeVoice-Realtime TTS has been successfully implemented on DGX Spark with full GPU acceleration, achieving a significant reduction in time to first audio from 2-3 seconds to just 766ms. This setup utilizes a streaming pipeline that integrates Whisper STT, Ollama LLM, and VibeVoice TTS, allowing for sentence-level streaming and continuous audio playback for enhanced responsiveness. A common issue with CUDA availability on DGX Spark can be resolved by ensuring PyTorch is installed with GPU support, using specific installation commands. The VibeVoice model offers different configurations, with the 0.5B model providing quicker response times and the 1.5B model offering advanced voice cloning capabilities. This matters because it highlights advancements in real-time voice assistant technology, improving user interaction through faster and more responsive audio processing.
Microsoft's VibeVoice-Realtime TTS has been successfully implemented on DGX Spark with full GPU acceleration, achieving a significant reduction in time to first audio from 2-3 seconds to just 766ms. This setup utilizes a streaming pipeline that integrates Whisper STT, Ollama LLM, and VibeVoice TTS, allowing for sentence-level streaming and continuous audio playback for enhanced responsiveness. A common issue with CUDA availability on DGX Spark can be resolved by ensuring PyTorch is installed with GPU support, using specific installation commands. The VibeVoice model offers different configurations, with the 0.5B model providing quicker response times and the 1.5B model offering advanced voice cloning capabilities. This matters because it highlights advancements in real-time voice assistant technology, improving user interaction through faster and more responsive audio processing.
-
Visualizing DeepSeek’s mHC Training Fix
Read Full Article: Visualizing DeepSeek’s mHC Training Fix DeepSeek's recent paper introduces Manifold-Constrained Hyper-Connections (mHC) to address training instability in deep learning models with many layers. When stacking over 60 layers of learned mixing matrices, small amplifications can compound, leading to explosive growth in training gains. By projecting these matrices onto a "doubly stochastic" manifold using the Sinkhorn-Knopp algorithm, gains remain bounded regardless of depth, with just one iteration significantly reducing gain from 1016 to approximately 1. An interactive demo and PyTorch implementation are available for experimentation, illustrating how this approach effectively stabilizes training. This matters because it offers a solution to a critical challenge in scaling deep learning models safely and efficiently.
DeepSeek's recent paper introduces Manifold-Constrained Hyper-Connections (mHC) to address training instability in deep learning models with many layers. When stacking over 60 layers of learned mixing matrices, small amplifications can compound, leading to explosive growth in training gains. By projecting these matrices onto a "doubly stochastic" manifold using the Sinkhorn-Knopp algorithm, gains remain bounded regardless of depth, with just one iteration significantly reducing gain from 1016 to approximately 1. An interactive demo and PyTorch implementation are available for experimentation, illustrating how this approach effectively stabilizes training. This matters because it offers a solution to a critical challenge in scaling deep learning models safely and efficiently.
-
Interactive Visualization of DeepSeek’s mHC Stability
Read Full Article: Interactive Visualization of DeepSeek’s mHC Stability![[P] Interactive visualization of DeepSeek's mHC - why doubly stochastic constraints fix Hyper-Connection instability](https://www.tweakedgeek.com/wp-content/uploads/2026/01/featured-article-8316-300x171.png) An interactive demo has been created to explore DeepSeek's mHC paper, addressing the instability in Hyper-Connections caused by the multiplication of learned matrices across multiple layers. This instability results in exponential amplification, reaching values as high as 10^16. The solution involves projecting these matrices onto a doubly stochastic manifold using the Sinkhorn-Knopp algorithm, which ensures that the composite mapping remains bounded, regardless of depth. Surprisingly, just one iteration of the Sinkhorn process is sufficient to stabilize the gain from 10^16 to approximately 1. This matters because it offers a practical method to enhance the stability and performance of deep learning models that utilize Hyper-Connections.
An interactive demo has been created to explore DeepSeek's mHC paper, addressing the instability in Hyper-Connections caused by the multiplication of learned matrices across multiple layers. This instability results in exponential amplification, reaching values as high as 10^16. The solution involves projecting these matrices onto a doubly stochastic manifold using the Sinkhorn-Knopp algorithm, which ensures that the composite mapping remains bounded, regardless of depth. Surprisingly, just one iteration of the Sinkhorn process is sufficient to stabilize the gain from 10^16 to approximately 1. This matters because it offers a practical method to enhance the stability and performance of deep learning models that utilize Hyper-Connections.
-
WhisperNote: Local Transcription App for Windows
Read Full Article: WhisperNote: Local Transcription App for Windows WhisperNote is a Windows desktop application designed for local audio transcription using OpenAI Whisper, emphasizing simplicity and privacy. It allows users to either record audio directly or upload an audio file to receive a text transcription, with all processing conducted offline on the user's machine. This ensures no reliance on cloud services or the need for user accounts, aligning with a minimalistic and local-first approach. Although the Windows build is approximately 4 GB due to bundled dependencies like Python, PyTorch with CUDA, and FFmpeg, it provides a comprehensive offline experience. This matters because it offers a straightforward and private solution for users seeking a reliable transcription tool without internet dependency.
WhisperNote is a Windows desktop application designed for local audio transcription using OpenAI Whisper, emphasizing simplicity and privacy. It allows users to either record audio directly or upload an audio file to receive a text transcription, with all processing conducted offline on the user's machine. This ensures no reliance on cloud services or the need for user accounts, aligning with a minimalistic and local-first approach. Although the Windows build is approximately 4 GB due to bundled dependencies like Python, PyTorch with CUDA, and FFmpeg, it provides a comprehensive offline experience. This matters because it offers a straightforward and private solution for users seeking a reliable transcription tool without internet dependency.
-
160x Speedup in Nudity Detection with ONNX & PyTorch
Read Full Article: 160x Speedup in Nudity Detection with ONNX & PyTorchAn innovative approach to enhancing the efficiency of a nudity detection pipeline achieved a remarkable 160x speedup by utilizing a "headless" strategy with ONNX and PyTorch. The optimization involved converting the model to an ONNX format, which is more efficient for inference, and removing unnecessary components that do not contribute to the final prediction. This streamlined process not only improves performance but also reduces computational costs, making it more feasible for real-time applications. Such advancements are crucial for deploying AI models in environments where speed and resource efficiency are paramount.
-
LoureiroGate: Enforcing Hard Physical Constraints
Read Full Article: LoureiroGate: Enforcing Hard Physical Constraints![[Project] LoureiroGate: A PyTorch library for enforcing Hard Physical Constraints (Differentiable Gating)](https://www.tweakedgeek.com/wp-content/uploads/2025/12/featured-article-7603-300x171.png) Choosing the right programming language for machine learning can greatly affect efficiency, performance, and resource accessibility. Python is the most popular choice due to its ease of use, extensive library ecosystem, and strong community support, making it ideal for beginners and experienced developers alike. Other languages like R, Java, C++, Julia, Go, and Rust offer unique advantages for specific use cases, such as statistical analysis, enterprise integration, or performance-critical tasks. The best language depends on individual needs and the specific requirements of the machine learning project. This matters because selecting the appropriate programming language can significantly streamline machine learning development and enhance the effectiveness of the solutions created.
Choosing the right programming language for machine learning can greatly affect efficiency, performance, and resource accessibility. Python is the most popular choice due to its ease of use, extensive library ecosystem, and strong community support, making it ideal for beginners and experienced developers alike. Other languages like R, Java, C++, Julia, Go, and Rust offer unique advantages for specific use cases, such as statistical analysis, enterprise integration, or performance-critical tasks. The best language depends on individual needs and the specific requirements of the machine learning project. This matters because selecting the appropriate programming language can significantly streamline machine learning development and enhance the effectiveness of the solutions created.
-
The State Of LLMs 2025: Progress, Problems, Predictions
Read Full Article: The State Of LLMs 2025: Progress, Problems, Predictions![[P] The State Of LLMs 2025: Progress, Problems, and Predictions](https://www.tweakedgeek.com/wp-content/uploads/2025/12/featured-article-7469-300x171.png) Choosing the right machine learning framework is crucial for development efficiency and model performance. PyTorch and TensorFlow are two of the most recommended frameworks, with TensorFlow being favored in industrial settings due to its robust tools and Keras integration, which simplifies development. However, some users find TensorFlow setup challenging, particularly on Windows due to the lack of native GPU support. Other notable frameworks include JAX, Scikit-Learn, and XGBoost, with various subreddits offering platforms for further discussion and personalized advice from experienced practitioners. This matters because selecting an appropriate machine learning framework can significantly influence the success and efficiency of AI projects.
Choosing the right machine learning framework is crucial for development efficiency and model performance. PyTorch and TensorFlow are two of the most recommended frameworks, with TensorFlow being favored in industrial settings due to its robust tools and Keras integration, which simplifies development. However, some users find TensorFlow setup challenging, particularly on Windows due to the lack of native GPU support. Other notable frameworks include JAX, Scikit-Learn, and XGBoost, with various subreddits offering platforms for further discussion and personalized advice from experienced practitioners. This matters because selecting an appropriate machine learning framework can significantly influence the success and efficiency of AI projects.
-
Federated Fraud Detection with PyTorch
Read Full Article: Federated Fraud Detection with PyTorch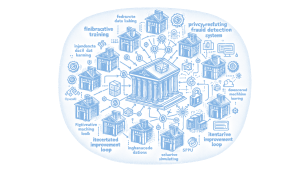 A privacy-preserving fraud detection system is simulated using Federated Learning, allowing ten independent banks to train local fraud-detection models on imbalanced transaction data. The system utilizes a FedAvg aggregation loop to improve a global model without sharing raw transaction data between clients. OpenAI is integrated to provide post-training analysis and risk-oriented reporting, transforming federated learning outputs into actionable insights. This approach emphasizes privacy, simplicity, and real-world applicability, offering a practical blueprint for experimenting with federated fraud models. Understanding and implementing such systems is crucial for enhancing fraud detection while maintaining data privacy.
A privacy-preserving fraud detection system is simulated using Federated Learning, allowing ten independent banks to train local fraud-detection models on imbalanced transaction data. The system utilizes a FedAvg aggregation loop to improve a global model without sharing raw transaction data between clients. OpenAI is integrated to provide post-training analysis and risk-oriented reporting, transforming federated learning outputs into actionable insights. This approach emphasizes privacy, simplicity, and real-world applicability, offering a practical blueprint for experimenting with federated fraud models. Understanding and implementing such systems is crucial for enhancing fraud detection while maintaining data privacy.
-
Four Ways to Run ONNX AI Models on GPU with CUDA
Read Full Article: Four Ways to Run ONNX AI Models on GPU with CUDA Running ONNX AI models on GPUs with CUDA can be achieved through four distinct methods, enhancing flexibility and performance for machine learning operations. These methods include using ONNX Runtime with CUDA execution provider, leveraging TensorRT for optimized inference, employing PyTorch with its ONNX export capabilities, and utilizing the NVIDIA Triton Inference Server for scalable deployment. Each approach offers unique advantages, such as improved speed, ease of integration, or scalability, catering to different needs in AI model deployment. Understanding these options is crucial for optimizing AI workloads and ensuring efficient use of GPU resources.
Running ONNX AI models on GPUs with CUDA can be achieved through four distinct methods, enhancing flexibility and performance for machine learning operations. These methods include using ONNX Runtime with CUDA execution provider, leveraging TensorRT for optimized inference, employing PyTorch with its ONNX export capabilities, and utilizing the NVIDIA Triton Inference Server for scalable deployment. Each approach offers unique advantages, such as improved speed, ease of integration, or scalability, catering to different needs in AI model deployment. Understanding these options is crucial for optimizing AI workloads and ensuring efficient use of GPU resources.