Deep Dives
-
Building Self-Organizing Zettelkasten Knowledge Graphs
Read Full Article: Building Self-Organizing Zettelkasten Knowledge Graphs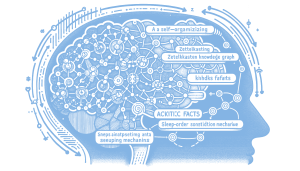 Building a self-organizing Zettelkasten knowledge graph with sleep-consolidation mechanisms represents a significant leap in Agentic AI, mimicking the human brain's ability to organize and consolidate information. By using Google's Gemini, the system autonomously decomposes inputs into atomic facts, semantically links them, and consolidates these into higher-order insights, akin to how the brain processes and stores memories. This approach allows the agent to actively understand and adapt to evolving project contexts, addressing the issue of fragmented context in long-running AI interactions. The implementation includes robust error handling for API constraints, ensuring smooth operation even under heavy processing loads. This matters because it demonstrates the potential for creating more intelligent, autonomous agents that can manage complex information dynamically, paving the way for advanced AI applications.
Building a self-organizing Zettelkasten knowledge graph with sleep-consolidation mechanisms represents a significant leap in Agentic AI, mimicking the human brain's ability to organize and consolidate information. By using Google's Gemini, the system autonomously decomposes inputs into atomic facts, semantically links them, and consolidates these into higher-order insights, akin to how the brain processes and stores memories. This approach allows the agent to actively understand and adapt to evolving project contexts, addressing the issue of fragmented context in long-running AI interactions. The implementation includes robust error handling for API constraints, ensuring smooth operation even under heavy processing loads. This matters because it demonstrates the potential for creating more intelligent, autonomous agents that can manage complex information dynamically, paving the way for advanced AI applications.
-
Zahaviel Structured Intelligence: A New Cognitive OS
Read Full Article: Zahaviel Structured Intelligence: A New Cognitive OS![[P] Zahaviel Structured Intelligence: A Recursive Cognitive Operating System for Externalized Thought (Paper)](https://www.tweakedgeek.com/wp-content/uploads/2025/12/featured-article-5999-1-300x171.png) Zahaviel Structured Intelligence introduces a novel cognitive architecture that diverges from traditional token prediction and transformer models, focusing instead on a recursion-first approach. This system emphasizes recursive validation loops as its core processing unit, structured field encoding where meaning is defined by position and relation, and a full trace lineage of outputs ensuring that every result is verifiable and reconstructible. The architecture is designed to externalize cognition through schema-preserving outputs, allowing for interface-anchored thought processes. Key components include a recursive kernel for self-validating transformations, trace anchors for comprehensive output lineage tracking, and field samplers that manage relational input/output modules. This approach operationalizes thought by embedding structural history and constraints within every output, offering a new paradigm for non-linear AI cognition and memory-integrated systems. Understanding this architecture is crucial for advancing AI systems that mimic human-like thought processes more authentically.
Zahaviel Structured Intelligence introduces a novel cognitive architecture that diverges from traditional token prediction and transformer models, focusing instead on a recursion-first approach. This system emphasizes recursive validation loops as its core processing unit, structured field encoding where meaning is defined by position and relation, and a full trace lineage of outputs ensuring that every result is verifiable and reconstructible. The architecture is designed to externalize cognition through schema-preserving outputs, allowing for interface-anchored thought processes. Key components include a recursive kernel for self-validating transformations, trace anchors for comprehensive output lineage tracking, and field samplers that manage relational input/output modules. This approach operationalizes thought by embedding structural history and constraints within every output, offering a new paradigm for non-linear AI cognition and memory-integrated systems. Understanding this architecture is crucial for advancing AI systems that mimic human-like thought processes more authentically.
-
Top 7 Open Source OCR Models
Read Full Article: Top 7 Open Source OCR Models Optical Character Recognition (OCR) models are evolving rapidly, offering advanced capabilities that surpass traditional text extraction methods. Modern open-source OCR models can transform documents, tables, diagrams, and multilingual text into highly accurate digital copies. These models are not only more efficient but also provide enhanced accuracy, making them suitable for a variety of applications, from parsing PDFs to processing multilingual documents. The latest models offer features like adaptive content-aware processing, reinforcement learning optimization, and scalable toolkit support, which are critical for handling complex document layouts and large-scale processing tasks. Among the top OCR models, olmOCR-2-7B-1025 stands out for its high accuracy in document OCR, particularly for scientific and technical PDFs, while PaddleOCR v5 excels in multilingual parsing across 109 languages. OCRFlux-3B offers markdown-accurate parsing with advanced cross-page table and paragraph merging, optimized for consumer GPUs. MiniCPM-V 4.5 provides state-of-the-art multimodal OCR, supporting video understanding and mobile device deployment. InternVL 2.5-4B is designed for resource-limited environments, offering efficient OCR with multimodal reasoning. Granite Vision 3.3 2b focuses on visual document understanding, including experimental features like image segmentation and doctags generation. Lastly, TrOCR Large Printed is specialized for clean printed-text OCR, leveraging transformer-based architecture for high-quality text extraction. The advancements in OCR technology are significant as they enable more efficient and accurate document processing across various industries. These models support a wide range of applications, from enterprise document extraction to mobile and edge OCR tasks, enhancing the ability to digitize and analyze complex documents efficiently. This matters because it empowers businesses and individuals to automate and improve the accuracy of data extraction, leading to better decision-making and streamlined workflows.
Optical Character Recognition (OCR) models are evolving rapidly, offering advanced capabilities that surpass traditional text extraction methods. Modern open-source OCR models can transform documents, tables, diagrams, and multilingual text into highly accurate digital copies. These models are not only more efficient but also provide enhanced accuracy, making them suitable for a variety of applications, from parsing PDFs to processing multilingual documents. The latest models offer features like adaptive content-aware processing, reinforcement learning optimization, and scalable toolkit support, which are critical for handling complex document layouts and large-scale processing tasks. Among the top OCR models, olmOCR-2-7B-1025 stands out for its high accuracy in document OCR, particularly for scientific and technical PDFs, while PaddleOCR v5 excels in multilingual parsing across 109 languages. OCRFlux-3B offers markdown-accurate parsing with advanced cross-page table and paragraph merging, optimized for consumer GPUs. MiniCPM-V 4.5 provides state-of-the-art multimodal OCR, supporting video understanding and mobile device deployment. InternVL 2.5-4B is designed for resource-limited environments, offering efficient OCR with multimodal reasoning. Granite Vision 3.3 2b focuses on visual document understanding, including experimental features like image segmentation and doctags generation. Lastly, TrOCR Large Printed is specialized for clean printed-text OCR, leveraging transformer-based architecture for high-quality text extraction. The advancements in OCR technology are significant as they enable more efficient and accurate document processing across various industries. These models support a wide range of applications, from enterprise document extraction to mobile and edge OCR tasks, enhancing the ability to digitize and analyze complex documents efficiently. This matters because it empowers businesses and individuals to automate and improve the accuracy of data extraction, leading to better decision-making and streamlined workflows.
-
Programming Languages for Machine Learning
Read Full Article: Programming Languages for Machine Learning Python reigns supreme in the realm of machine learning due to its extensive libraries and user-friendly nature, making it the go-to language for many developers. However, when performance or platform-specific needs arise, other programming languages come into play. C++ is often employed for performance-critical components of machine learning projects. Julia, although not as widely adopted, is another language some developers use for its capabilities in this field. R is mainly utilized for statistical analysis and data visualization but also supports machine learning tasks. Go, with its high-level language features and efficient performance, is another option for machine learning applications. Swift, commonly used for iOS and macOS development, is also applicable to machine learning, while Kotlin is preferred for Android development, including machine learning inference on mobile devices. Java, with tools like GraalVM, and Rust, known for performance and memory safety, are also viable choices for machine learning projects. Languages like Dart, which compiles to machine code for various architectures, and Vala, suitable for general-purpose programming, can also be used in machine learning contexts. Although Python remains the most popular and versatile language for machine learning, familiarity with other languages such as C++, Julia, R, Go, Swift, Kotlin, Java, Rust, Dart, and Vala can enhance a developer's toolkit for specific performance or platform requirements. A strong grasp of programming fundamentals and AI principles is crucial, regardless of the language used. This matters because understanding the strengths of different programming languages can optimize machine learning projects for performance and platform compatibility.
Python reigns supreme in the realm of machine learning due to its extensive libraries and user-friendly nature, making it the go-to language for many developers. However, when performance or platform-specific needs arise, other programming languages come into play. C++ is often employed for performance-critical components of machine learning projects. Julia, although not as widely adopted, is another language some developers use for its capabilities in this field. R is mainly utilized for statistical analysis and data visualization but also supports machine learning tasks. Go, with its high-level language features and efficient performance, is another option for machine learning applications. Swift, commonly used for iOS and macOS development, is also applicable to machine learning, while Kotlin is preferred for Android development, including machine learning inference on mobile devices. Java, with tools like GraalVM, and Rust, known for performance and memory safety, are also viable choices for machine learning projects. Languages like Dart, which compiles to machine code for various architectures, and Vala, suitable for general-purpose programming, can also be used in machine learning contexts. Although Python remains the most popular and versatile language for machine learning, familiarity with other languages such as C++, Julia, R, Go, Swift, Kotlin, Java, Rust, Dart, and Vala can enhance a developer's toolkit for specific performance or platform requirements. A strong grasp of programming fundamentals and AI principles is crucial, regardless of the language used. This matters because understanding the strengths of different programming languages can optimize machine learning projects for performance and platform compatibility.
-
Sketch to HTML with Qwen3-VL
Read Full Article: Sketch to HTML with Qwen3-VL Qwen3-VL is showcased as a powerful tool for developing a sketch-to-HTML application, highlighting its practical application in creating real-world solutions. The process involves using Qwen3-VL to convert hand-drawn sketches into functional HTML code, demonstrating the model's capability to bridge the gap between design and development. This approach not only streamlines the workflow for designers and developers but also exemplifies how advanced machine learning models can be harnessed to automate and enhance creative processes. Understanding and implementing such technology can significantly improve efficiency in web development projects, making it a valuable asset for both individual developers and teams.
Qwen3-VL is showcased as a powerful tool for developing a sketch-to-HTML application, highlighting its practical application in creating real-world solutions. The process involves using Qwen3-VL to convert hand-drawn sketches into functional HTML code, demonstrating the model's capability to bridge the gap between design and development. This approach not only streamlines the workflow for designers and developers but also exemplifies how advanced machine learning models can be harnessed to automate and enhance creative processes. Understanding and implementing such technology can significantly improve efficiency in web development projects, making it a valuable asset for both individual developers and teams.
-
Step-by-Step EDA: Raw Data to Visual Insights
Read Full Article: Step-by-Step EDA: Raw Data to Visual Insights A comprehensive Exploratory Data Analysis (EDA) notebook has been developed, focusing on the process of transforming raw data into meaningful visual insights using Python. The notebook covers essential EDA techniques such as handling missing values and outliers, which are crucial for preparing data for analysis. By addressing these common data issues, users can ensure that their analysis is based on accurate and complete datasets, leading to more reliable conclusions. Feature correlation heatmaps are also included, which help in identifying relationships between different variables within a dataset. These visual tools allow users to quickly spot patterns and correlations that might not be immediately apparent through raw data alone. The notebook utilizes popular Python libraries such as matplotlib and seaborn to create interactive visualizations, making it easier for users to explore and understand complex datasets visually. The EDA notebook uses the Fifa 19 dataset to demonstrate these techniques, offering key insights into the data while maintaining clean and well-documented code. This approach ensures that even beginners can follow along and apply these methods to their own datasets. By sharing this resource, the author invites feedback and encourages learning and collaboration within the data science community. This matters because effective EDA is foundational to data-driven decision-making and can significantly enhance the quality of insights derived from data.
A comprehensive Exploratory Data Analysis (EDA) notebook has been developed, focusing on the process of transforming raw data into meaningful visual insights using Python. The notebook covers essential EDA techniques such as handling missing values and outliers, which are crucial for preparing data for analysis. By addressing these common data issues, users can ensure that their analysis is based on accurate and complete datasets, leading to more reliable conclusions. Feature correlation heatmaps are also included, which help in identifying relationships between different variables within a dataset. These visual tools allow users to quickly spot patterns and correlations that might not be immediately apparent through raw data alone. The notebook utilizes popular Python libraries such as matplotlib and seaborn to create interactive visualizations, making it easier for users to explore and understand complex datasets visually. The EDA notebook uses the Fifa 19 dataset to demonstrate these techniques, offering key insights into the data while maintaining clean and well-documented code. This approach ensures that even beginners can follow along and apply these methods to their own datasets. By sharing this resource, the author invites feedback and encourages learning and collaboration within the data science community. This matters because effective EDA is foundational to data-driven decision-making and can significantly enhance the quality of insights derived from data.
-
Exploring Programming Languages for Machine Learning
Read Full Article: Exploring Programming Languages for Machine Learning Python remains the dominant programming language in the field of machine learning due to its extensive libraries and ease of use. However, for performance-critical tasks, C++ is often employed to optimize speed and efficiency. Although not as widely adopted, Julia is another language that some developers have turned to for machine learning applications. R is primarily used for statistical analysis and data visualization, but it also offers capabilities for machine learning. Go, with its ability to compile to native code and features like garbage collection, provides good performance for high-level programming. Swift, typically used for iOS and macOS development, and Kotlin, favored for Android development, are both high-level languages that compile to machine code and are applicable to machine learning tasks. Java, with tools like GraalVM, can be compiled natively, making it suitable for performance-sensitive ML applications. Rust is appreciated for its performance and memory safety, making it a strong candidate for high-performance computing in machine learning. Other languages like Dart, which compiles to machine code for various architectures, and Vala, which compiles to native code, also offer potential for ML development. Understanding these languages alongside Python can provide developers with a versatile toolkit for addressing specific performance or platform requirements in machine learning projects. This matters because choosing the right programming language can significantly impact the efficiency and success of machine learning applications.
Python remains the dominant programming language in the field of machine learning due to its extensive libraries and ease of use. However, for performance-critical tasks, C++ is often employed to optimize speed and efficiency. Although not as widely adopted, Julia is another language that some developers have turned to for machine learning applications. R is primarily used for statistical analysis and data visualization, but it also offers capabilities for machine learning. Go, with its ability to compile to native code and features like garbage collection, provides good performance for high-level programming. Swift, typically used for iOS and macOS development, and Kotlin, favored for Android development, are both high-level languages that compile to machine code and are applicable to machine learning tasks. Java, with tools like GraalVM, can be compiled natively, making it suitable for performance-sensitive ML applications. Rust is appreciated for its performance and memory safety, making it a strong candidate for high-performance computing in machine learning. Other languages like Dart, which compiles to machine code for various architectures, and Vala, which compiles to native code, also offer potential for ML development. Understanding these languages alongside Python can provide developers with a versatile toolkit for addressing specific performance or platform requirements in machine learning projects. This matters because choosing the right programming language can significantly impact the efficiency and success of machine learning applications.
-
Pre-Transformer NLP Research Insights
Read Full Article: Pre-Transformer NLP Research Insights Python remains the dominant programming language for machine learning due to its extensive libraries and user-friendly nature. However, other languages are employed for specific purposes, particularly when performance or platform-specific needs arise. C++ is often used for performance-critical parts of machine learning, while Julia, although less widely adopted, is recognized for its capabilities in this field. R is primarily utilized for statistical analysis and data visualization but also supports machine learning tasks. Go, known for its compiled native code and garbage collection, offers good performance as a high-level language. Swift, typically used for iOS and macOS development, is applicable to machine learning due to its compilation to machine code. Kotlin, preferred over Java for Android development, supports machine learning inference on mobile devices. Java, with tools like GraalVM, can be compiled natively, making it suitable for performance-sensitive applications, including machine learning inference. Rust is favored for its performance and memory safety, making it a strong candidate for high-performance computing tasks in machine learning. Dart and Vala also compile to machine code for various architectures, offering versatility in machine learning applications. While Python's popularity and versatility make it the go-to language for machine learning, familiarity with other languages such as C++, Julia, R, Go, Swift, Kotlin, Java, Rust, Dart, and Vala can provide additional tools for addressing specific performance or platform requirements. A solid understanding of programming fundamentals and AI principles remains crucial, regardless of the language used. This matters because diversifying language skills can enhance problem-solving capabilities and optimize machine learning solutions across different environments and applications.
Python remains the dominant programming language for machine learning due to its extensive libraries and user-friendly nature. However, other languages are employed for specific purposes, particularly when performance or platform-specific needs arise. C++ is often used for performance-critical parts of machine learning, while Julia, although less widely adopted, is recognized for its capabilities in this field. R is primarily utilized for statistical analysis and data visualization but also supports machine learning tasks. Go, known for its compiled native code and garbage collection, offers good performance as a high-level language. Swift, typically used for iOS and macOS development, is applicable to machine learning due to its compilation to machine code. Kotlin, preferred over Java for Android development, supports machine learning inference on mobile devices. Java, with tools like GraalVM, can be compiled natively, making it suitable for performance-sensitive applications, including machine learning inference. Rust is favored for its performance and memory safety, making it a strong candidate for high-performance computing tasks in machine learning. Dart and Vala also compile to machine code for various architectures, offering versatility in machine learning applications. While Python's popularity and versatility make it the go-to language for machine learning, familiarity with other languages such as C++, Julia, R, Go, Swift, Kotlin, Java, Rust, Dart, and Vala can provide additional tools for addressing specific performance or platform requirements. A solid understanding of programming fundamentals and AI principles remains crucial, regardless of the language used. This matters because diversifying language skills can enhance problem-solving capabilities and optimize machine learning solutions across different environments and applications.
-
Training a Model for Code Edit Predictions
Read Full Article: Training a Model for Code Edit Predictions Developing a coding agent like NES, designed to predict the next change needed in a code file, is a complex task that requires understanding how developers write and edit code. The model considers the entire file and recent edit history to predict where and what the next change should be. Capturing real developer intent is challenging due to the messy nature of real commits, which often include unrelated changes and skip incremental steps. To train the edit model effectively, special edit tokens were used to define editable regions, cursor positions, and intended edits, allowing the model to predict the next code edit within a specified region. Data sources like CommitPackFT and Zeta were utilized, and the dataset was normalized into a unified format with filtering to remove non-sequential edits. The choice of base model for fine-tuning was crucial, with Gemini 2.5 Flash Lite selected for its ease of use and operational efficiency. This managed model avoids the overhead of running an open-source model and uses LoRA for lightweight fine-tuning, ensuring the model remains stable and cost-effective. Flash Lite enhances user experience by providing faster responses and lower compute costs, enabling frequent improvements without significant downtime or version drift. Evaluation of the edit model was conducted using the LLM-as-a-Judge metric, which assesses the semantic correctness and logical consistency of predicted edits. This approach is more aligned with human judgment than simple token-level comparisons, allowing for scalable and sensitive evaluation processes. To make the Next Edit Suggestions responsive, the model receives more than just the current file snapshot at inference time; it also includes the user's recent edit history and additional semantic context. This comprehensive input helps the model understand user intent and predict the next edit accurately. This matters because it enhances coding efficiency and accuracy, offering developers a more intuitive and reliable tool for code editing.
Developing a coding agent like NES, designed to predict the next change needed in a code file, is a complex task that requires understanding how developers write and edit code. The model considers the entire file and recent edit history to predict where and what the next change should be. Capturing real developer intent is challenging due to the messy nature of real commits, which often include unrelated changes and skip incremental steps. To train the edit model effectively, special edit tokens were used to define editable regions, cursor positions, and intended edits, allowing the model to predict the next code edit within a specified region. Data sources like CommitPackFT and Zeta were utilized, and the dataset was normalized into a unified format with filtering to remove non-sequential edits. The choice of base model for fine-tuning was crucial, with Gemini 2.5 Flash Lite selected for its ease of use and operational efficiency. This managed model avoids the overhead of running an open-source model and uses LoRA for lightweight fine-tuning, ensuring the model remains stable and cost-effective. Flash Lite enhances user experience by providing faster responses and lower compute costs, enabling frequent improvements without significant downtime or version drift. Evaluation of the edit model was conducted using the LLM-as-a-Judge metric, which assesses the semantic correctness and logical consistency of predicted edits. This approach is more aligned with human judgment than simple token-level comparisons, allowing for scalable and sensitive evaluation processes. To make the Next Edit Suggestions responsive, the model receives more than just the current file snapshot at inference time; it also includes the user's recent edit history and additional semantic context. This comprehensive input helps the model understand user intent and predict the next edit accurately. This matters because it enhances coding efficiency and accuracy, offering developers a more intuitive and reliable tool for code editing.
-
Building a Small VIT with Streamlit
Read Full Article: Building a Small VIT with Streamlit Streamlit is a popular framework for creating data applications with ease, and its capabilities are being explored through a project involving small Vision Transformers (VITs). The project involves performing a grid search on custom-built VITs to identify the most effective configuration for real-time digit classification. By leveraging Streamlit, the project not only facilitates the classification process but also provides a platform to visualize attention maps, which are crucial for understanding how the model focuses on different parts of the input data. The use of VITs in this context is significant as they represent a modern approach to handling image data, often outperforming traditional convolutional neural networks in various tasks. The project demonstrates how VITs can be effectively implemented from scratch and highlights the flexibility of Streamlit in deploying machine learning models. This exploration serves as a practical example for those looking to understand the integration of advanced machine learning techniques with user-friendly application frameworks. Sharing the code and application through platforms like GitHub and Streamlit allows others to replicate and learn from the project, fostering a collaborative learning environment. This is particularly useful for individuals new to Streamlit or those interested in experimenting with VITs, providing them with a tangible example to build upon. The project not only showcases the potential of Streamlit in machine learning applications but also encourages others to explore and innovate within the field. This matters because it highlights the accessibility and power of modern tools in democratizing machine learning development.
Streamlit is a popular framework for creating data applications with ease, and its capabilities are being explored through a project involving small Vision Transformers (VITs). The project involves performing a grid search on custom-built VITs to identify the most effective configuration for real-time digit classification. By leveraging Streamlit, the project not only facilitates the classification process but also provides a platform to visualize attention maps, which are crucial for understanding how the model focuses on different parts of the input data. The use of VITs in this context is significant as they represent a modern approach to handling image data, often outperforming traditional convolutional neural networks in various tasks. The project demonstrates how VITs can be effectively implemented from scratch and highlights the flexibility of Streamlit in deploying machine learning models. This exploration serves as a practical example for those looking to understand the integration of advanced machine learning techniques with user-friendly application frameworks. Sharing the code and application through platforms like GitHub and Streamlit allows others to replicate and learn from the project, fostering a collaborative learning environment. This is particularly useful for individuals new to Streamlit or those interested in experimenting with VITs, providing them with a tangible example to build upon. The project not only showcases the potential of Streamlit in machine learning applications but also encourages others to explore and innovate within the field. This matters because it highlights the accessibility and power of modern tools in democratizing machine learning development.