AI models
-
Naver Launches HyperCLOVA X SEED Models
Read Full Article: Naver Launches HyperCLOVA X SEED Models Naver has introduced HyperCLOVA X SEED Think, a 32-billion parameter open weights reasoning model, and HyperCLOVA X SEED 8B Omni, a unified multimodal model that integrates text, vision, and speech. These advancements are part of a broader trend in 2025 where local language models (LLMs) are evolving rapidly, with llama.cpp gaining popularity for its performance and flexibility. Mixture of Experts (MoE) models are becoming favored for their efficiency on consumer hardware, while new local LLMs are enhancing capabilities in vision and multimodal applications. Additionally, Retrieval-Augmented Generation (RAG) systems are being used to mimic continuous learning, and advancements in high-VRAM hardware are expanding the potential of local models. This matters because it highlights the ongoing innovation and accessibility in AI technologies, making advanced capabilities more available to a wider range of users.
Naver has introduced HyperCLOVA X SEED Think, a 32-billion parameter open weights reasoning model, and HyperCLOVA X SEED 8B Omni, a unified multimodal model that integrates text, vision, and speech. These advancements are part of a broader trend in 2025 where local language models (LLMs) are evolving rapidly, with llama.cpp gaining popularity for its performance and flexibility. Mixture of Experts (MoE) models are becoming favored for their efficiency on consumer hardware, while new local LLMs are enhancing capabilities in vision and multimodal applications. Additionally, Retrieval-Augmented Generation (RAG) systems are being used to mimic continuous learning, and advancements in high-VRAM hardware are expanding the potential of local models. This matters because it highlights the ongoing innovation and accessibility in AI technologies, making advanced capabilities more available to a wider range of users.
-
Tencent’s WeDLM 8B Instruct on Hugging Face
Read Full Article: Tencent’s WeDLM 8B Instruct on Hugging Face In 2025, significant advancements in Llama AI technology and local large language models (LLMs) have been observed. The llama.cpp has become the preferred choice for many users due to its superior performance and flexibility, as well as its direct integration with Llama models. Mixture of Experts (MoE) models are gaining popularity for their efficient use of consumer hardware, balancing performance with resource usage. New local LLMs with enhanced vision and multimodal capabilities are emerging, offering improved versatility for various applications. Although continuous retraining of LLMs is challenging, Retrieval-Augmented Generation (RAG) systems are being used to mimic continuous learning by integrating external knowledge bases. Advances in high-VRAM hardware are enabling the use of larger models on consumer-grade machines, expanding the potential of local LLMs. This matters because it highlights the rapid evolution and accessibility of AI technologies, which can significantly impact various industries and consumer applications.
In 2025, significant advancements in Llama AI technology and local large language models (LLMs) have been observed. The llama.cpp has become the preferred choice for many users due to its superior performance and flexibility, as well as its direct integration with Llama models. Mixture of Experts (MoE) models are gaining popularity for their efficient use of consumer hardware, balancing performance with resource usage. New local LLMs with enhanced vision and multimodal capabilities are emerging, offering improved versatility for various applications. Although continuous retraining of LLMs is challenging, Retrieval-Augmented Generation (RAG) systems are being used to mimic continuous learning by integrating external knowledge bases. Advances in high-VRAM hardware are enabling the use of larger models on consumer-grade machines, expanding the potential of local LLMs. This matters because it highlights the rapid evolution and accessibility of AI technologies, which can significantly impact various industries and consumer applications.
-
Axiomatic Convergence in Generative Systems
Read Full Article: Axiomatic Convergence in Generative SystemsThe Axiomatic Convergence Hypothesis (ACH) explores how generative systems behave under fixed external constraints, proposing that repeated generation under stable conditions leads to reduced variability. The concept of "axiomatic convergence" is defined with a focus on both output and structural convergence, and the hypothesis includes predictions about convergence patterns such as variance decay and path dependence. A detailed experimental protocol is provided for testing ACH across various models and domains, emphasizing independent replication without revealing proprietary details. This work aims to foster understanding and analysis of convergence in generative systems, offering a framework for consistent evaluation. This matters because it provides a structured approach to understanding and predicting behavior in complex generative systems, which can enhance the development and reliability of AI models.
-
Titans + MIRAS: AI’s Long-Term Memory Breakthrough
Read Full Article: Titans + MIRAS: AI’s Long-Term Memory Breakthrough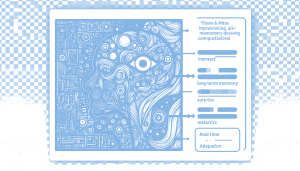 The Transformer architecture, known for its attention mechanism, faces challenges in handling extremely long sequences due to high computational costs. To address this, researchers have explored efficient models like linear RNNs and state space models. However, these models struggle with capturing the complexity of very long sequences. The Titans architecture and MIRAS framework present a novel solution by combining the speed of RNNs with the accuracy of transformers, enabling AI models to maintain long-term memory through real-time adaptation and powerful "surprise" metrics. This approach allows models to continuously update their parameters with new information, enhancing their ability to process and understand extensive data streams. This matters because it significantly enhances AI's capability to handle complex, long-term data, crucial for applications like full-document understanding and genomic analysis.
The Transformer architecture, known for its attention mechanism, faces challenges in handling extremely long sequences due to high computational costs. To address this, researchers have explored efficient models like linear RNNs and state space models. However, these models struggle with capturing the complexity of very long sequences. The Titans architecture and MIRAS framework present a novel solution by combining the speed of RNNs with the accuracy of transformers, enabling AI models to maintain long-term memory through real-time adaptation and powerful "surprise" metrics. This approach allows models to continuously update their parameters with new information, enhancing their ability to process and understand extensive data streams. This matters because it significantly enhances AI's capability to handle complex, long-term data, crucial for applications like full-document understanding and genomic analysis.
-
AI Model Predicts EV Charging Port Availability
Read Full Article: AI Model Predicts EV Charging Port Availability A simple AI model has been developed to predict the availability of electric vehicle (EV) charging ports, aiming to reduce range anxiety for EV users. The model was rigorously tested against a strong baseline that assumes no change in port availability, which is often accurate due to the low frequency of changes in port status. By focusing on mean squared error (MSE) and mean absolute error (MAE) as key metrics, the model assesses the likelihood of at least one port being available, a critical factor for EV users planning their charging stops. This advancement matters as it enhances the reliability of EV charging infrastructure, potentially increasing consumer confidence in electric vehicles.
A simple AI model has been developed to predict the availability of electric vehicle (EV) charging ports, aiming to reduce range anxiety for EV users. The model was rigorously tested against a strong baseline that assumes no change in port availability, which is often accurate due to the low frequency of changes in port status. By focusing on mean squared error (MSE) and mean absolute error (MAE) as key metrics, the model assesses the likelihood of at least one port being available, a critical factor for EV users planning their charging stops. This advancement matters as it enhances the reliability of EV charging infrastructure, potentially increasing consumer confidence in electric vehicles.
-
Tiny AI Models for Raspberry Pi
Read Full Article: Tiny AI Models for Raspberry Pi Advancements in AI have enabled the development of tiny models that can run efficiently on devices with limited resources, such as the Raspberry Pi. These models, including Qwen3, Exaone, Ministral, Jamba Reasoning, Granite, and Phi-4 Mini, leverage modern architectures and quantization techniques to deliver high performance in tasks like text generation, vision understanding, and tool usage. Despite their small size, they outperform older, larger models in real-world applications, offering capabilities such as long-context processing, multilingual support, and efficient reasoning. These models demonstrate that compact AI systems can be both powerful and practical for low-power devices, making local AI inference more accessible and cost-effective. This matters because it highlights the potential for deploying advanced AI capabilities on everyday devices, broadening the scope of AI applications without the need for extensive computing infrastructure.
Advancements in AI have enabled the development of tiny models that can run efficiently on devices with limited resources, such as the Raspberry Pi. These models, including Qwen3, Exaone, Ministral, Jamba Reasoning, Granite, and Phi-4 Mini, leverage modern architectures and quantization techniques to deliver high performance in tasks like text generation, vision understanding, and tool usage. Despite their small size, they outperform older, larger models in real-world applications, offering capabilities such as long-context processing, multilingual support, and efficient reasoning. These models demonstrate that compact AI systems can be both powerful and practical for low-power devices, making local AI inference more accessible and cost-effective. This matters because it highlights the potential for deploying advanced AI capabilities on everyday devices, broadening the scope of AI applications without the need for extensive computing infrastructure.
-
Expanding Partnership with UK AI Security Institute
Read Full Article: Expanding Partnership with UK AI Security Institute Google DeepMind is expanding its partnership with the UK AI Security Institute (AISI) to enhance the safety and responsibility of AI development. This collaboration aims to accelerate research progress by sharing proprietary models and data, conducting joint publications, and engaging in collaborative security and safety research. Key areas of focus include monitoring AI reasoning processes, understanding the social and emotional impacts of AI, and evaluating the economic implications of AI on real-world tasks. The partnership underscores a commitment to realizing the benefits of AI while mitigating potential risks, supported by rigorous testing, safety training, and collaboration with independent experts. This matters because ensuring AI systems are developed safely and responsibly is crucial for maximizing their potential benefits to society.
Google DeepMind is expanding its partnership with the UK AI Security Institute (AISI) to enhance the safety and responsibility of AI development. This collaboration aims to accelerate research progress by sharing proprietary models and data, conducting joint publications, and engaging in collaborative security and safety research. Key areas of focus include monitoring AI reasoning processes, understanding the social and emotional impacts of AI, and evaluating the economic implications of AI on real-world tasks. The partnership underscores a commitment to realizing the benefits of AI while mitigating potential risks, supported by rigorous testing, safety training, and collaboration with independent experts. This matters because ensuring AI systems are developed safely and responsibly is crucial for maximizing their potential benefits to society.
-
NVIDIA’s NitroGen: AI Model for Gaming Agents
Read Full Article: NVIDIA’s NitroGen: AI Model for Gaming Agents NVIDIA's AI research team has introduced NitroGen, a groundbreaking vision action foundation model designed for generalist gaming agents. NitroGen learns to play commercial games directly from visual data and gamepad actions, utilizing a vast dataset of 40,000 hours of gameplay from over 1,000 games. The model employs a sophisticated action extraction pipeline to convert video data into actionable insights, enabling it to achieve significant task completion rates across various gaming genres without reinforcement learning. NitroGen's unified controller action space allows for seamless policy transfer across multiple games, demonstrating improved performance when fine-tuned on new titles. This advancement matters because it showcases the potential of AI to autonomously learn complex tasks from large-scale, diverse data sources, paving the way for more versatile and adaptive AI systems in gaming and beyond.
NVIDIA's AI research team has introduced NitroGen, a groundbreaking vision action foundation model designed for generalist gaming agents. NitroGen learns to play commercial games directly from visual data and gamepad actions, utilizing a vast dataset of 40,000 hours of gameplay from over 1,000 games. The model employs a sophisticated action extraction pipeline to convert video data into actionable insights, enabling it to achieve significant task completion rates across various gaming genres without reinforcement learning. NitroGen's unified controller action space allows for seamless policy transfer across multiple games, demonstrating improved performance when fine-tuned on new titles. This advancement matters because it showcases the potential of AI to autonomously learn complex tasks from large-scale, diverse data sources, paving the way for more versatile and adaptive AI systems in gaming and beyond.
-
GLM vs MiniMax: A Comparative Analysis
Read Full Article: GLM vs MiniMax: A Comparative Analysis GLM is praised for its ability to produce clear, maintainable code compared to MiniMax, which is criticized for generating complex and difficult-to-debug outputs. Despite some claims that MiniMax is superior, GLM is favored for its intelligibility and ease of use, especially after minor corrective prompts. In the Chinese AI landscape, GLM is considered significantly more advanced than other models like MiniMax 2.1, DeepSeek v3.2, and the Qwen series. This matters because choosing the right AI model can significantly impact the efficiency and effectiveness of coding tasks.
GLM is praised for its ability to produce clear, maintainable code compared to MiniMax, which is criticized for generating complex and difficult-to-debug outputs. Despite some claims that MiniMax is superior, GLM is favored for its intelligibility and ease of use, especially after minor corrective prompts. In the Chinese AI landscape, GLM is considered significantly more advanced than other models like MiniMax 2.1, DeepSeek v3.2, and the Qwen series. This matters because choosing the right AI model can significantly impact the efficiency and effectiveness of coding tasks.
-
Four Ways to Run ONNX AI Models on GPU with CUDA
Read Full Article: Four Ways to Run ONNX AI Models on GPU with CUDA Running ONNX AI models on GPUs with CUDA can be achieved through four distinct methods, enhancing flexibility and performance for machine learning operations. These methods include using ONNX Runtime with CUDA execution provider, leveraging TensorRT for optimized inference, employing PyTorch with its ONNX export capabilities, and utilizing the NVIDIA Triton Inference Server for scalable deployment. Each approach offers unique advantages, such as improved speed, ease of integration, or scalability, catering to different needs in AI model deployment. Understanding these options is crucial for optimizing AI workloads and ensuring efficient use of GPU resources.
Running ONNX AI models on GPUs with CUDA can be achieved through four distinct methods, enhancing flexibility and performance for machine learning operations. These methods include using ONNX Runtime with CUDA execution provider, leveraging TensorRT for optimized inference, employing PyTorch with its ONNX export capabilities, and utilizing the NVIDIA Triton Inference Server for scalable deployment. Each approach offers unique advantages, such as improved speed, ease of integration, or scalability, catering to different needs in AI model deployment. Understanding these options is crucial for optimizing AI workloads and ensuring efficient use of GPU resources.