NoHypeTech
-
Grafted Titans: Enhancing LLMs with Neural Memory
Read Full Article: Grafted Titans: Enhancing LLMs with Neural Memory An experiment with Test-Time Training (TTT) aimed to replicate Google's "Titans" architecture by grafting a trainable memory module onto a frozen open-weight model, Qwen-2.5-0.5B, using consumer-grade hardware. This new architecture, called "Grafted Titans," appends memory embeddings to the input layer through a trainable cross-attention gating mechanism, allowing the memory to update while the base model remains static. In tests using the BABILong benchmark, the Grafted Titans model achieved 44.7% accuracy, outperforming the vanilla Qwen model's 34.0% accuracy by acting as a denoising filter. However, the model faces limitations such as signal dilution and susceptibility to input poisoning, and further research is needed to address these issues. This matters because it explores innovative ways to enhance neural network performance without extensive computational resources, potentially democratizing access to advanced AI capabilities.
An experiment with Test-Time Training (TTT) aimed to replicate Google's "Titans" architecture by grafting a trainable memory module onto a frozen open-weight model, Qwen-2.5-0.5B, using consumer-grade hardware. This new architecture, called "Grafted Titans," appends memory embeddings to the input layer through a trainable cross-attention gating mechanism, allowing the memory to update while the base model remains static. In tests using the BABILong benchmark, the Grafted Titans model achieved 44.7% accuracy, outperforming the vanilla Qwen model's 34.0% accuracy by acting as a denoising filter. However, the model faces limitations such as signal dilution and susceptibility to input poisoning, and further research is needed to address these issues. This matters because it explores innovative ways to enhance neural network performance without extensive computational resources, potentially democratizing access to advanced AI capabilities.
-
Understanding Multilinear Regression
Read Full Article: Understanding Multilinear Regression Multilinear regression extends the concept of simple linear regression by incorporating multiple features, allowing the model to explore additional dimensions beyond a single line. Each new feature adds a new direction, transforming the model's output space from a line to a plane, and eventually to a hyperplane as more features are added. This expansion of the output space means that the set of reachable outputs becomes larger, which can reduce error or maintain it, as the model gains the ability to move in more directions. Understanding this concept is crucial for leveraging multilinear regression to improve model accuracy and performance.
Multilinear regression extends the concept of simple linear regression by incorporating multiple features, allowing the model to explore additional dimensions beyond a single line. Each new feature adds a new direction, transforming the model's output space from a line to a plane, and eventually to a hyperplane as more features are added. This expansion of the output space means that the set of reachable outputs becomes larger, which can reduce error or maintain it, as the model gains the ability to move in more directions. Understanding this concept is crucial for leveraging multilinear regression to improve model accuracy and performance.
-
AI Reasoning System with Unlimited Context Window
Read Full Article: AI Reasoning System with Unlimited Context Window A groundbreaking AI reasoning system has been developed, boasting an unlimited context window that has left researchers astounded. This advancement allows the AI to process and understand information without the constraints of traditional context windows, which typically limit the amount of data the AI can consider at once. By removing these limitations, the AI is capable of more sophisticated reasoning and decision-making, potentially transforming applications in fields such as natural language processing and complex problem-solving. This matters because it opens up new possibilities for AI to handle more complex tasks and datasets, enhancing its utility and effectiveness across various domains.
A groundbreaking AI reasoning system has been developed, boasting an unlimited context window that has left researchers astounded. This advancement allows the AI to process and understand information without the constraints of traditional context windows, which typically limit the amount of data the AI can consider at once. By removing these limitations, the AI is capable of more sophisticated reasoning and decision-making, potentially transforming applications in fields such as natural language processing and complex problem-solving. This matters because it opens up new possibilities for AI to handle more complex tasks and datasets, enhancing its utility and effectiveness across various domains.
-
DGX Spark: Discrepancies in Nvidia’s LLM Benchmarks
Read Full Article: DGX Spark: Discrepancies in Nvidia’s LLM Benchmarks DGX Spark, Nvidia's platform for large language model (LLM) development, has been found to perform significantly slower than Nvidia's advertised benchmarks. While Nvidia claims high token processing speeds using advanced frameworks like Unsloth, real-world tests show much lower performance, suggesting potential discrepancies in Nvidia's reported figures. The tests indicate that Nvidia may be using specialized low precision training methods not commonly accessible, or possibly overstating their benchmarks. This discrepancy is crucial for developers and researchers to consider when planning investments in AI hardware, as it impacts the efficiency and cost-effectiveness of LLM training.
DGX Spark, Nvidia's platform for large language model (LLM) development, has been found to perform significantly slower than Nvidia's advertised benchmarks. While Nvidia claims high token processing speeds using advanced frameworks like Unsloth, real-world tests show much lower performance, suggesting potential discrepancies in Nvidia's reported figures. The tests indicate that Nvidia may be using specialized low precision training methods not commonly accessible, or possibly overstating their benchmarks. This discrepancy is crucial for developers and researchers to consider when planning investments in AI hardware, as it impacts the efficiency and cost-effectiveness of LLM training.
-
Visualizing DeepSeek’s mHC Training Fix
Read Full Article: Visualizing DeepSeek’s mHC Training Fix DeepSeek's recent paper introduces Manifold-Constrained Hyper-Connections (mHC) to address training instability in deep learning models with many layers. When stacking over 60 layers of learned mixing matrices, small amplifications can compound, leading to explosive growth in training gains. By projecting these matrices onto a "doubly stochastic" manifold using the Sinkhorn-Knopp algorithm, gains remain bounded regardless of depth, with just one iteration significantly reducing gain from 1016 to approximately 1. An interactive demo and PyTorch implementation are available for experimentation, illustrating how this approach effectively stabilizes training. This matters because it offers a solution to a critical challenge in scaling deep learning models safely and efficiently.
DeepSeek's recent paper introduces Manifold-Constrained Hyper-Connections (mHC) to address training instability in deep learning models with many layers. When stacking over 60 layers of learned mixing matrices, small amplifications can compound, leading to explosive growth in training gains. By projecting these matrices onto a "doubly stochastic" manifold using the Sinkhorn-Knopp algorithm, gains remain bounded regardless of depth, with just one iteration significantly reducing gain from 1016 to approximately 1. An interactive demo and PyTorch implementation are available for experimentation, illustrating how this approach effectively stabilizes training. This matters because it offers a solution to a critical challenge in scaling deep learning models safely and efficiently.
-
Manifold-Constrained Hyper-Connections in AI
Read Full Article: Manifold-Constrained Hyper-Connections in AI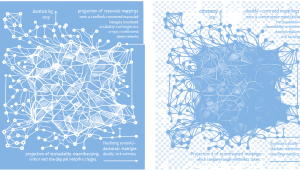 DeepSeek-AI introduces Manifold-Constrained Hyper-Connections (mHC) to tackle the instability and scalability challenges of Hyper-Connections (HC) in neural networks. The approach involves projecting residual mappings onto a constrained manifold using doubly stochastic matrices via the Sinkhorn-Knopp algorithm, which helps maintain the identity mapping property while benefiting from enhanced residual streams. This method has shown to improve training stability and scalability in large-scale language model pretraining, with negligible additional system overhead. Such advancements are crucial for developing more efficient and robust AI models capable of handling complex tasks at scale.
DeepSeek-AI introduces Manifold-Constrained Hyper-Connections (mHC) to tackle the instability and scalability challenges of Hyper-Connections (HC) in neural networks. The approach involves projecting residual mappings onto a constrained manifold using doubly stochastic matrices via the Sinkhorn-Knopp algorithm, which helps maintain the identity mapping property while benefiting from enhanced residual streams. This method has shown to improve training stability and scalability in large-scale language model pretraining, with negligible additional system overhead. Such advancements are crucial for developing more efficient and robust AI models capable of handling complex tasks at scale.
-
Maincode/Maincoder-1B Support in llama.cpp
Read Full Article: Maincode/Maincoder-1B Support in llama.cppRecent advancements in Llama AI technology include the integration of support for Maincode/Maincoder-1B into llama.cpp, showcasing the ongoing evolution of AI frameworks. Meta's latest developments are accompanied by internal tensions and leadership challenges, yet the community remains optimistic about future predictions and practical applications. Notably, the "Awesome AI Apps" GitHub repository serves as a valuable resource for AI agent examples across frameworks like LangChain and LlamaIndex. Additionally, a RAG-based multilingual AI system utilizing Llama 3.1 has been developed for agro-ecological decision support, highlighting a significant real-world application of this technology. This matters because it demonstrates the expanding capabilities and practical uses of AI in diverse fields, from agriculture to software development.
-
Lynkr – Multi-Provider LLM Proxy
Read Full Article: Lynkr – Multi-Provider LLM Proxy The landscape of local Large Language Models (LLMs) is rapidly advancing, with llama.cpp emerging as a preferred choice among redditors for its superior performance, transparency, and features compared to Ollama. While several local LLMs have proven effective for various tasks, the latest Llama models have received mixed reviews. The rising costs of hardware, especially VRAM and DRAM, pose challenges for running local LLMs. For those seeking further insights and community discussions, several subreddits offer valuable resources and support. Understanding these developments is crucial as they impact the accessibility and efficiency of AI technologies in local settings.
The landscape of local Large Language Models (LLMs) is rapidly advancing, with llama.cpp emerging as a preferred choice among redditors for its superior performance, transparency, and features compared to Ollama. While several local LLMs have proven effective for various tasks, the latest Llama models have received mixed reviews. The rising costs of hardware, especially VRAM and DRAM, pose challenges for running local LLMs. For those seeking further insights and community discussions, several subreddits offer valuable resources and support. Understanding these developments is crucial as they impact the accessibility and efficiency of AI technologies in local settings.
-
Training a Custom YOLO Model for Posture Detection
Read Full Article: Training a Custom YOLO Model for Posture Detection Embarking on a machine learning journey, a newcomer trained a YOLO classification model to detect poor sitting posture, discovering valuable insights and challenges. While pose estimation initially seemed promising, it failed to deliver results, and the YOLO model struggled with partial side views, highlighting the limitations of pre-trained models. The experience underscored that a lower training loss doesn't guarantee a better model, as evidenced by overfitting when validation accuracy remained unchanged. Utilizing the early stopping parameter proved crucial in optimizing training time, and converting the model from .pt to TensorRT significantly improved inference speed, doubling the frame rate from 15 to 30 FPS. Understanding these nuances is essential for efficient and effective model training in machine learning projects.
Embarking on a machine learning journey, a newcomer trained a YOLO classification model to detect poor sitting posture, discovering valuable insights and challenges. While pose estimation initially seemed promising, it failed to deliver results, and the YOLO model struggled with partial side views, highlighting the limitations of pre-trained models. The experience underscored that a lower training loss doesn't guarantee a better model, as evidenced by overfitting when validation accuracy remained unchanged. Utilizing the early stopping parameter proved crucial in optimizing training time, and converting the model from .pt to TensorRT significantly improved inference speed, doubling the frame rate from 15 to 30 FPS. Understanding these nuances is essential for efficient and effective model training in machine learning projects.
-
Building Paradox-Proof AI with CFOL Layers
Read Full Article: Building Paradox-Proof AI with CFOL Layers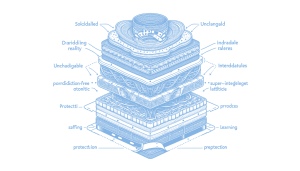 Building superintelligent AI requires addressing fundamental issues like paradoxes and deception that arise from current AI architectures. Traditional models, such as those used by ChatGPT and Claude, manipulate truth as a variable, leading to problems like scheming and hallucinations. The CFOL (Contradiction-Free Ontological Lattice) framework proposes a layered approach that separates immutable reality from flexible learning processes, preventing paradoxes and ensuring stable, reliable AI behavior. This structural fix is akin to adding seatbelts in cars, providing a necessary foundation for safe and effective AI development. Understanding and implementing CFOL is essential to overcoming the limitations of flat AI architectures and achieving true superintelligence.
Building superintelligent AI requires addressing fundamental issues like paradoxes and deception that arise from current AI architectures. Traditional models, such as those used by ChatGPT and Claude, manipulate truth as a variable, leading to problems like scheming and hallucinations. The CFOL (Contradiction-Free Ontological Lattice) framework proposes a layered approach that separates immutable reality from flexible learning processes, preventing paradoxes and ensuring stable, reliable AI behavior. This structural fix is akin to adding seatbelts in cars, providing a necessary foundation for safe and effective AI development. Understanding and implementing CFOL is essential to overcoming the limitations of flat AI architectures and achieving true superintelligence.