Deep Dives
-
Web Control Center for llama.cpp
Read Full Article: Web Control Center for llama.cpp A new web control center has been developed for managing llama.cpp instances more efficiently, addressing common issues such as optimal parameter calculation, port management, and log access. It features automatic hardware detection to recommend optimal settings like n_ctx, n_gpu_layers, and n_threads, and allows for multi-server management with a user-friendly interface. The system includes a built-in chat interface, performance benchmarking, and real-time log streaming, all built on a FastAPI backend and Vanilla JS frontend. The project seeks feedback on parameter recommendations, testing on various hardware setups, and ideas for enterprise features, with potential for future monetization through GitHub Sponsors and Pro features. This matters because it streamlines the management of llama.cpp instances, enhancing efficiency and performance for users.
A new web control center has been developed for managing llama.cpp instances more efficiently, addressing common issues such as optimal parameter calculation, port management, and log access. It features automatic hardware detection to recommend optimal settings like n_ctx, n_gpu_layers, and n_threads, and allows for multi-server management with a user-friendly interface. The system includes a built-in chat interface, performance benchmarking, and real-time log streaming, all built on a FastAPI backend and Vanilla JS frontend. The project seeks feedback on parameter recommendations, testing on various hardware setups, and ideas for enterprise features, with potential for future monetization through GitHub Sponsors and Pro features. This matters because it streamlines the management of llama.cpp instances, enhancing efficiency and performance for users.
-
MiniMax M2.1 Quantization: Q6 vs. Q8 Experience
Read Full Article: MiniMax M2.1 Quantization: Q6 vs. Q8 Experience Using Bartowski's Q6_K quantization of MiniMax M2.1 on llama.cpp's server led to difficulties in generating accurate unit tests for a function called interval2short(), which formats time intervals into short strings. The Q6 quantization struggled to correctly identify the output format, often engaging in extensive and redundant processing without arriving at the correct result. In contrast, upgrading to Q8 quantization resolved these issues efficiently, achieving correct results with fewer tokens. Despite the advantage of Q6 fitting entirely in VRAM, the performance of Q8 suggests it may be worth the extra effort to manage GPU allocations for better accuracy. This matters because choosing the right model quantization can significantly impact the efficiency and accuracy of coding tasks.
Using Bartowski's Q6_K quantization of MiniMax M2.1 on llama.cpp's server led to difficulties in generating accurate unit tests for a function called interval2short(), which formats time intervals into short strings. The Q6 quantization struggled to correctly identify the output format, often engaging in extensive and redundant processing without arriving at the correct result. In contrast, upgrading to Q8 quantization resolved these issues efficiently, achieving correct results with fewer tokens. Despite the advantage of Q6 fitting entirely in VRAM, the performance of Q8 suggests it may be worth the extra effort to manage GPU allocations for better accuracy. This matters because choosing the right model quantization can significantly impact the efficiency and accuracy of coding tasks.
-
Visualizing DeepSeek’s mHC Training Fix
Read Full Article: Visualizing DeepSeek’s mHC Training Fix DeepSeek's recent paper introduces Manifold-Constrained Hyper-Connections (mHC) to address training instability in deep learning models with many layers. When stacking over 60 layers of learned mixing matrices, small amplifications can compound, leading to explosive growth in training gains. By projecting these matrices onto a "doubly stochastic" manifold using the Sinkhorn-Knopp algorithm, gains remain bounded regardless of depth, with just one iteration significantly reducing gain from 1016 to approximately 1. An interactive demo and PyTorch implementation are available for experimentation, illustrating how this approach effectively stabilizes training. This matters because it offers a solution to a critical challenge in scaling deep learning models safely and efficiently.
DeepSeek's recent paper introduces Manifold-Constrained Hyper-Connections (mHC) to address training instability in deep learning models with many layers. When stacking over 60 layers of learned mixing matrices, small amplifications can compound, leading to explosive growth in training gains. By projecting these matrices onto a "doubly stochastic" manifold using the Sinkhorn-Knopp algorithm, gains remain bounded regardless of depth, with just one iteration significantly reducing gain from 1016 to approximately 1. An interactive demo and PyTorch implementation are available for experimentation, illustrating how this approach effectively stabilizes training. This matters because it offers a solution to a critical challenge in scaling deep learning models safely and efficiently.
-
Interactive Visualization of DeepSeek’s mHC Stability
Read Full Article: Interactive Visualization of DeepSeek’s mHC Stability![[P] Interactive visualization of DeepSeek's mHC - why doubly stochastic constraints fix Hyper-Connection instability](https://www.tweakedgeek.com/wp-content/uploads/2026/01/featured-article-8316-300x171.png) An interactive demo has been created to explore DeepSeek's mHC paper, addressing the instability in Hyper-Connections caused by the multiplication of learned matrices across multiple layers. This instability results in exponential amplification, reaching values as high as 10^16. The solution involves projecting these matrices onto a doubly stochastic manifold using the Sinkhorn-Knopp algorithm, which ensures that the composite mapping remains bounded, regardless of depth. Surprisingly, just one iteration of the Sinkhorn process is sufficient to stabilize the gain from 10^16 to approximately 1. This matters because it offers a practical method to enhance the stability and performance of deep learning models that utilize Hyper-Connections.
An interactive demo has been created to explore DeepSeek's mHC paper, addressing the instability in Hyper-Connections caused by the multiplication of learned matrices across multiple layers. This instability results in exponential amplification, reaching values as high as 10^16. The solution involves projecting these matrices onto a doubly stochastic manifold using the Sinkhorn-Knopp algorithm, which ensures that the composite mapping remains bounded, regardless of depth. Surprisingly, just one iteration of the Sinkhorn process is sufficient to stabilize the gain from 10^16 to approximately 1. This matters because it offers a practical method to enhance the stability and performance of deep learning models that utilize Hyper-Connections.
-
Manifold-Constrained Hyper-Connections in AI
Read Full Article: Manifold-Constrained Hyper-Connections in AI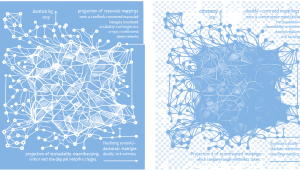 DeepSeek-AI introduces Manifold-Constrained Hyper-Connections (mHC) to tackle the instability and scalability challenges of Hyper-Connections (HC) in neural networks. The approach involves projecting residual mappings onto a constrained manifold using doubly stochastic matrices via the Sinkhorn-Knopp algorithm, which helps maintain the identity mapping property while benefiting from enhanced residual streams. This method has shown to improve training stability and scalability in large-scale language model pretraining, with negligible additional system overhead. Such advancements are crucial for developing more efficient and robust AI models capable of handling complex tasks at scale.
DeepSeek-AI introduces Manifold-Constrained Hyper-Connections (mHC) to tackle the instability and scalability challenges of Hyper-Connections (HC) in neural networks. The approach involves projecting residual mappings onto a constrained manifold using doubly stochastic matrices via the Sinkhorn-Knopp algorithm, which helps maintain the identity mapping property while benefiting from enhanced residual streams. This method has shown to improve training stability and scalability in large-scale language model pretraining, with negligible additional system overhead. Such advancements are crucial for developing more efficient and robust AI models capable of handling complex tasks at scale.
-
Maincode/Maincoder-1B Support in llama.cpp
Read Full Article: Maincode/Maincoder-1B Support in llama.cppRecent advancements in Llama AI technology include the integration of support for Maincode/Maincoder-1B into llama.cpp, showcasing the ongoing evolution of AI frameworks. Meta's latest developments are accompanied by internal tensions and leadership challenges, yet the community remains optimistic about future predictions and practical applications. Notably, the "Awesome AI Apps" GitHub repository serves as a valuable resource for AI agent examples across frameworks like LangChain and LlamaIndex. Additionally, a RAG-based multilingual AI system utilizing Llama 3.1 has been developed for agro-ecological decision support, highlighting a significant real-world application of this technology. This matters because it demonstrates the expanding capabilities and practical uses of AI in diverse fields, from agriculture to software development.
-
Arizona Water Usage: Golf vs Data Centers
Read Full Article: Arizona Water Usage: Golf vs Data Centers In Maricopa County, Arizona, golf courses consume significantly more water than data centers, using approximately 29 billion gallons annually compared to the 905 million gallons used by data centers. Despite this disparity, data centers generate more tax revenue, contributing $863 million statewide in 2023, compared to $518 million from the golf industry in 2021. When evaluating tax revenue per gallon of water used, data centers are about 50 times more efficient. The broader context reveals that agriculture accounts for 70% of Arizona's water usage, while data centers use less than 0.1%. Understanding these figures can help reframe discussions around water usage priorities and economic contributions in Arizona.
In Maricopa County, Arizona, golf courses consume significantly more water than data centers, using approximately 29 billion gallons annually compared to the 905 million gallons used by data centers. Despite this disparity, data centers generate more tax revenue, contributing $863 million statewide in 2023, compared to $518 million from the golf industry in 2021. When evaluating tax revenue per gallon of water used, data centers are about 50 times more efficient. The broader context reveals that agriculture accounts for 70% of Arizona's water usage, while data centers use less than 0.1%. Understanding these figures can help reframe discussions around water usage priorities and economic contributions in Arizona.
-
Emergent Attractor Framework: Streamlit App Launch
Read Full Article: Emergent Attractor Framework: Streamlit App Launch![[Project] Emergent Attractor Framework – now a Streamlit app for alignment & entropy research](https://www.tweakedgeek.com/wp-content/uploads/2026/01/featured-article-8289-300x171.png) The Emergent Attractor Framework, now available as a Streamlit app, offers a novel approach to alignment and entropy research. This tool allows users to engage with complex concepts through an interactive platform, facilitating a deeper understanding of how systems self-organize and reach equilibrium states. By providing a space for community interaction, the app encourages collaborative exploration and discussion, making it a valuable resource for researchers and enthusiasts alike. This matters because it democratizes access to advanced research tools, fostering innovation and collaboration in the study of dynamic systems.
The Emergent Attractor Framework, now available as a Streamlit app, offers a novel approach to alignment and entropy research. This tool allows users to engage with complex concepts through an interactive platform, facilitating a deeper understanding of how systems self-organize and reach equilibrium states. By providing a space for community interaction, the app encourages collaborative exploration and discussion, making it a valuable resource for researchers and enthusiasts alike. This matters because it democratizes access to advanced research tools, fostering innovation and collaboration in the study of dynamic systems.
-
Temporal LoRA: Dynamic Adapter Router for GPT-2
Read Full Article: Temporal LoRA: Dynamic Adapter Router for GPT-2![[Experimental] "Temporal LoRA": A dynamic adapter router that switches context (Code vs. Lit) with 100% accuracy. Proof of concept on GPT-2.](https://www.tweakedgeek.com/wp-content/uploads/2026/01/featured-article-8275-300x171.png) Temporal LoRA introduces a dynamic adapter router that allows models to switch between different contexts, such as coding and literature, with 100% accuracy. By training distinct LoRA adapters for different styles and implementing a "Time Mixer" network, the system can dynamically activate the appropriate adapter based on input context, maintaining model stability while allowing for flexible task switching. This approach provides a promising method for integrating Mixture of Experts (MoE) in larger models without the need for extensive retraining, enabling seamless "hot-swapping" of skills and enhancing multi-tasking capabilities. This matters because it offers a scalable solution for improving AI model adaptability and efficiency in handling diverse tasks.
Temporal LoRA introduces a dynamic adapter router that allows models to switch between different contexts, such as coding and literature, with 100% accuracy. By training distinct LoRA adapters for different styles and implementing a "Time Mixer" network, the system can dynamically activate the appropriate adapter based on input context, maintaining model stability while allowing for flexible task switching. This approach provides a promising method for integrating Mixture of Experts (MoE) in larger models without the need for extensive retraining, enabling seamless "hot-swapping" of skills and enhancing multi-tasking capabilities. This matters because it offers a scalable solution for improving AI model adaptability and efficiency in handling diverse tasks.
-
Enhancing Multi-Agent System Reliability
Read Full Article: Enhancing Multi-Agent System Reliability Managing multi-agent systems effectively requires moving beyond simple chatroom-style collaborations, which can lead to issues like politeness loops and non-deterministic behavior. Treating agents as microservices with a deterministic orchestration layer can improve reliability, especially in local setups. Implementing hub-and-spoke routing, rigid state machines, and a standard Agent Manifest can help streamline interactions and reduce errors. These strategies aim to enhance the efficiency and reliability of complex workflows involving multiple specialized agents. Understanding and implementing such structures is crucial for improving the scalability and predictability of multi-agent systems.
Managing multi-agent systems effectively requires moving beyond simple chatroom-style collaborations, which can lead to issues like politeness loops and non-deterministic behavior. Treating agents as microservices with a deterministic orchestration layer can improve reliability, especially in local setups. Implementing hub-and-spoke routing, rigid state machines, and a standard Agent Manifest can help streamline interactions and reduce errors. These strategies aim to enhance the efficiency and reliability of complex workflows involving multiple specialized agents. Understanding and implementing such structures is crucial for improving the scalability and predictability of multi-agent systems.