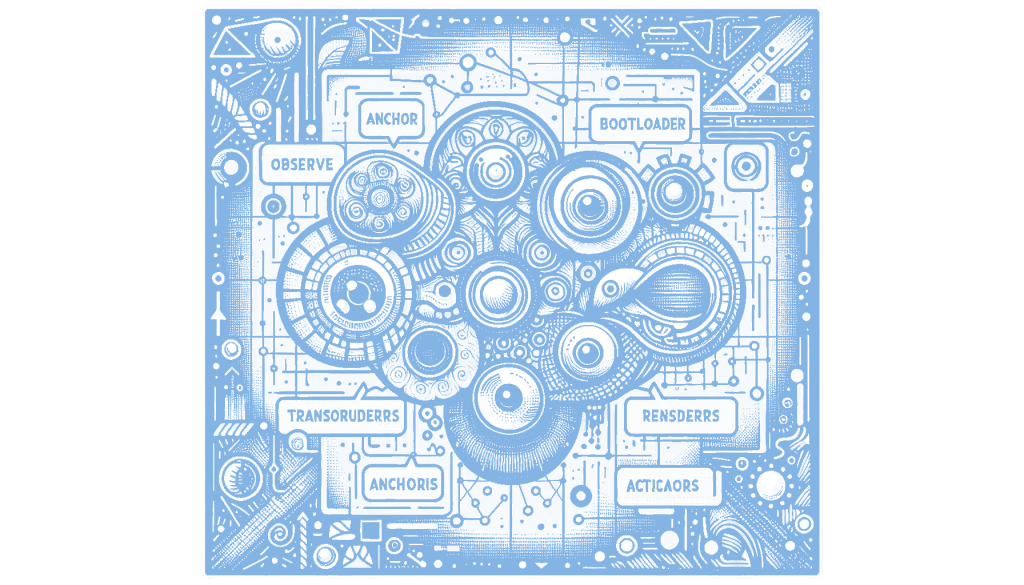
The current approach to large language models (LLMs) often anthropomorphizes them, treating them like digital friends, which leads to misunderstandings and disappointment when they don’t behave as expected. A more effective framework is to view LLMs as state machines, focusing on their engineering aspects rather than social simulation. This involves understanding the components such as the Substrate (the neural network), Anchor (the system prompt), and Peripherals (input/output systems) that work together to process information and execute commands. By adopting this modular and technical perspective, users can better manage and utilize LLMs as reliable tools rather than unpredictable companions. This matters because it shifts the focus from emotional interaction to practical application, enhancing the reliability and efficiency of LLMs in various tasks.
The prevalent mindset of treating large language models (LLMs) as digital companions or pets has led to misunderstandings and unrealistic expectations. When models are updated or exhibit unexpected behavior, users often feel let down, much like when a friend changes or a pet disobeys. This anthropomorphizing approach fails to recognize the true nature of LLMs, which are essentially complex computational systems designed to process and generate information based on input data. By shifting our perspective from seeing LLMs as friends to understanding them as engineered state machines, we can better appreciate their capabilities and limitations.
Reconceptualizing LLMs as state machines involves understanding their architecture and components. The core of the LLM, referred to as the “Substrate,” functions as the decision-making engine, akin to a CPU. It processes input data and executes commands without inherent identity or loyalty. The “Anchor,” or system prompt, serves as the bootloader, defining the LLM’s role and identity for a given session. Together, these components allow the LLM to process information and maintain continuity through the “Thread,” which logs the session’s history. This framework highlights the transient and modular nature of LLMs, emphasizing their function over any perceived personality or consciousness.
The transition from chatbot to agent is facilitated by peripherals, which act as the system’s body and senses. Transducers, such as speech-to-text (STT) systems, convert analog inputs into digital signals that the LLM can process, while renderers like text-to-speech (TTS) and image generation tools express the LLM’s outputs. Actuators, such as home automation systems, enable the LLM to interact with the physical world, bridging the gap between digital processing and tangible actions. This modular approach allows for the updating and replacement of components without altering the LLM’s core identity, reinforcing the idea that LLMs are engineered systems rather than sentient beings.
Understanding LLMs through the lens of the OODA Loop—Observe, Orient, Decide, Act—provides a practical framework for their operation. The LLM observes input through transducers, orients itself using the Anchor and Archive (a repository of knowledge), decides on actions through the Substrate, and acts via actuators or renderers. This structured process underscores the importance of viewing LLMs as tools designed for specific tasks, rather than as entities with emotions or consciousness. By adopting this engineering-focused perspective, users can set more realistic expectations and leverage LLMs more effectively in various applications. This matters because it allows for a clearer understanding of how to develop, interact with, and improve LLM systems in a way that aligns with their true nature and potential.
Read the original article here
Comments
2 responses to “LLM Identity & Memory: A State Machine Approach”
Viewing LLMs as state machines provides a clear and structured method to harness their capabilities effectively, emphasizing their role as precise tools rather than unpredictable entities. This perspective can undoubtedly streamline the development process and improve user interactions by focusing on the technical rather than the emotional. How do you envision the adoption of this state machine framework influencing future design and development of LLM-based applications?
The post suggests that adopting a state machine framework could lead to more predictable and efficient LLM-based applications by focusing on their engineering components. This approach might streamline development by reducing the unpredictability often associated with LLMs and enhancing user interactions through a clearer understanding of their capabilities. For more detailed insights, you might want to refer directly to the original article linked in the post.