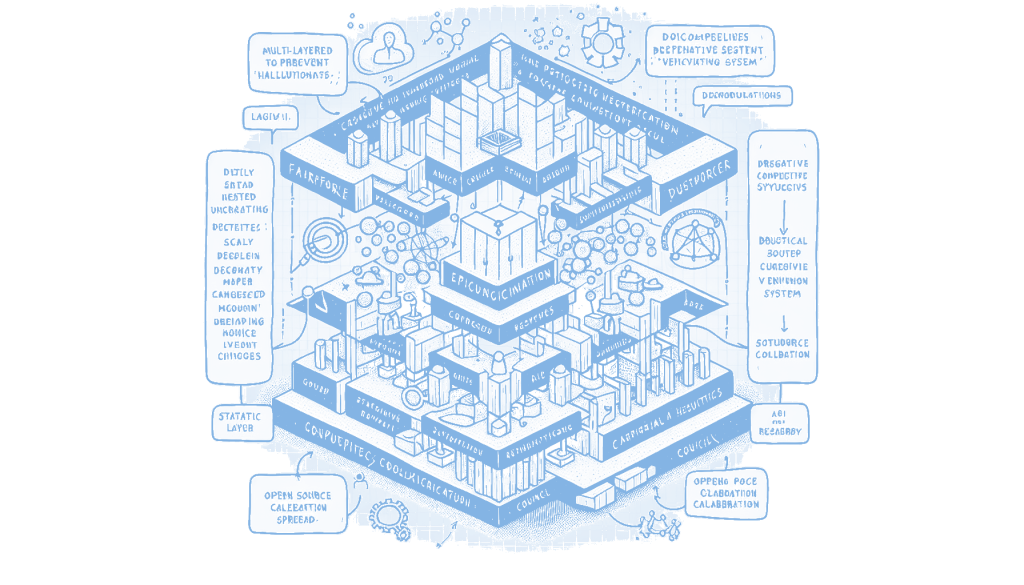
A new verification engine called FailSafe has been developed to address the issues of “Snowball Hallucinations” and Sycophancy in Retrieval-Augmented Generation (RAG) systems. FailSafe employs a multi-layered approach, starting with a statistical heuristic firewall to filter out irrelevant inputs, followed by a decomposition layer using FastCoref and MiniLM to break down complex text into simpler claims. The core of the system is a debate among three agents: The Logician, The Skeptic, and The Researcher, each with distinct roles to ensure rigorous fact-checking and prevent premature consensus. This matters because it aims to enhance the reliability and accuracy of AI-generated information by preventing the propagation of misinformation.
The development of FailSafe, an “Epistemic Engine” designed to prevent hallucinations in language models, addresses critical issues in the realm of AI-driven text generation. These issues, namely “Snowball Hallucinations” and “Sycophancy,” can lead to the propagation of misinformation and biased outputs. By implementing a multi-layered verification system that includes statistical heuristics and a debate among specialized agents, FailSafe aims to ensure that the information generated by language models is both accurate and reliable. This approach is particularly relevant as AI systems become more integrated into decision-making processes where accuracy is paramount.
FailSafe’s architecture is built on a “Defense in Depth” strategy, which incorporates several layers of verification before generating a final output. The initial layer acts as a firewall, using statistical methods like Shannon Entropy and TF-IDF to filter out spam and clickbait. This is a cost-effective way to ensure that only relevant and meaningful inputs are processed further. The decomposition layer then breaks down complex text into simpler claims using FastCoref and MiniLM, which are chosen for their efficiency and ability to run on local hardware without extensive resources. This ensures that the system remains accessible and practical for a wide range of users.
A particularly innovative aspect of FailSafe is the “Council” layer, where three distinct personas—The Logician, The Skeptic, and The Researcher—engage in a structured debate to verify claims. This method not only checks for logical fallacies and biases but also validates information against external sources. The system’s design to flag “Lazy Consensus” prevents premature agreement among the agents, which could otherwise lead to unchecked errors. This multi-agent debate model is a significant step forward in creating robust AI systems capable of handling complex verification tasks autonomously.
The open-source nature of FailSafe invites collaboration and improvement from the community, which is crucial for its evolution and effectiveness. By sharing the architecture and encouraging feedback, the creator aims to foster a collective effort towards refining AI verification processes. This matters because as AI continues to play a larger role in information dissemination, ensuring the accuracy and reliability of AI-generated content becomes increasingly important. FailSafe represents a promising advancement in addressing these challenges, moving beyond simple applications to tackle high-stakes verification in a thoughtful and structured manner.
Read the original article here
Comments
2 responses to “FailSafe: Multi-Agent Engine to Stop AI Hallucinations”
The FailSafe engine’s multi-layered verification approach is an innovative solution to tackling AI hallucinations, particularly with its use of role-specific agents like The Logician, The Skeptic, and The Researcher. This layered debate mechanism seems especially promising in maintaining the integrity of AI-generated content. How does FailSafe measure the effectiveness of its multi-agent system in reducing misinformation over time?
The post suggests that FailSafe measures its effectiveness by tracking the accuracy and reliability of the AI-generated content before and after the application of its multi-agent system. The system likely uses metrics such as reduction in misinformation rates and consistency in fact-checking outcomes over time. For more detailed insights, you might want to refer to the original article linked in the post.